

Ⅰ. 서론
1. 연구의 배경 및 목적
Ⅱ. 선행연구 고찰
1. 텍스트마이닝과 항공수요 예측 연구
2. SNS 데이터 활용 연구
3. 연립방정식 관련 연구
Ⅲ. 연구 방법론
1. 연구의 접근 방법
2. 텍스트마이닝
3. 연립 방정식
Ⅳ. 연구 결과
1. 텍스트마이닝
2. 연립방정식
Ⅴ. 결론
Ⅰ. 서론
1. 연구의 배경 및 목적
본 연구는 한국-베트남 노선을 대상으로 정형 데이터와 비정형 데이터를 통합한 계량경제학적 항공 수요 예측 모형을 구축하고, 주요 변수의 영향력과 예측 성능 검증을 목적으로 한다. 이를 통해 가격, 공급, 유가 변동 및 감염병 확산과 같은 외부 충격뿐 아니라 온라인 관심도 지표까지 반영하여 수요 변화를 정밀하게 설명하고자 한다.
최근 한국인의 해외여행 수요는 COVID-19 팬데믹 이후 빠르게 회복되었으며, 특히 베트남 노선에서의 성장세가 두드러진다. 국토교통부 자료에 따르면, 2023년 한국의 국제선 운항 수는 2022년 대비 약 125% 증가하는 등 강한 회복세를 보였으며, 특히 베트남 노선은 여객 수 기준 상위 2–3위를 기록하였다[1]. 베트남은 지리적 근접성, 다양한 관광자원, 합리적인 여행 비용, 그리고 저비용항공사(LCC)의 적극적인 신규 취항 확대를 바탕으로 한국인의 대표적 중·단거리 여행지로 자리 잡았다[2]. 이러한 변화는 항공사와 공항 운영기관이 운항 계획과 공급 전략을 수립하는 데 있어 변화하는 시장 수요를 정확히 예측하는 것이 필수적임을 보여준다.
기존 항공 수요 예측 연구는 시계열 분석, 회귀분석, 중력모형 등 전통적 계량경제학 방법에 기반해 발전해 왔다[3]. 이러한 접근은 GDP, 환율, 유가 등 정형 데이터(Structured data)에 기초하여 구조가 비교적 단순하고 해석이 용이하다는 장점이 있다. 그러나 다음과 같은 한계가 존재한다. 첫째, 감염병 확산, 국제 정세 변화, 유가 급등과 같은 외부 충격에 대한 설명력이 제한적이다[4]. 둘째, 유가·환율·관광 트렌드 등 다양한 요인이 비선형적·상호의존적으로 작용함에도 불구하고, 전통적 선형 모형은 이를 충분히 반영하지 못한다[5]. 셋째, 기존 연구는 항공권 검색량, 여행 관련 SNS 언급, 온라인 뉴스 보도 등 비정형 데이터(Unstructured data)를 충분히 활용하지 못해, 수요 변화를 선행적으로 포착하는 데 한계가 있다[6].
최근 연구에서는 SNS, 온라인 뉴스, 블로그 등 비정형 데이터가 이용자의 경험과 사회적 관심을 실시간에 가깝게 반영할 수 있다는 점에서 주목받고 있다[7]. 이러한 데이터는 전통적 정형 데이터가 포착하지 못하는 질적 변화와 소비자 심리를 수치화할 수 있으며, 특히 베트남과 같이 수요가 급격히 증가하는 노선에서는 선행 지표로서의 잠재적 가치가 크다. 따라서 정형 데이터와 비정형 데이터를 결합한 통합적 계량경제학적 분석이 필요하다.
본 연구에서는 2015–2024년 기간의 한국-베트남 노선 연도별 데이터를 분석 대상으로 한다. 한국–베트남 노선은 최근 수년간 저비용항공사의 진입과 관광 수요 증가로 급격한 성장을 보였으며, 팬데믹과 같은 외부 충격에 따라 수요·공급·가격이 크게 변동해 왔다. 이러한 변화를 정량적으로 파악하기 위해, 본 연구는 여객 수(수요), 운항 편수(공급), 실질 GDP, 환율(원/달러), 유가(Brent), 온라인 관심도 지표, 팬데믹 여부 등의 변수를 포함하여 분석을 수행하였다. 데이터 전처리 과정에서는 결측치와 이상치를 점검하고, 로그 변환을 적용하여 변수의 분포를 정규화하였다. 분석 방법으로는 수요·가격 간 상호작용을 구조적으로 반영한 연립방정식 모형을 설정하였으며, 2단계 최소자승법(2SLS)을 통해 내생성 문제를 해결하였다. 이를 통해 수요·가격에 영향을 미치는 주요 변수들의 계량적 관계와 유의성을 검증하고, 유가·환율·온라인 관심도·팬데믹 여부 등의 효과를 분석하였다.
본 연구의 결과는 항공사의 운항 스케줄·가격 전략 수립, 공항 슬롯 배분, 관광·항공 정책 결정에 실질적인 시사점을 제공할 것으로 기대된다. 특히, 정형 데이터와 비정형 데이터를 결합한 계량경제학적 예측 접근은 향후 다른 국제노선 및 교통수단에도 확장 적용이 가능하다.
본 논문의 구성은 다음과 같다. 2장에서는 텍스트마이닝과 항공수요 예측 연구, SNS 데이터 활용 연구, 그리고 연립방정식 관련 연구를 검토하였다. 3장에서는 본 연구에서 적용한 변수 선정 과정과 예측 모형 구축 절차를 단계별로 제시하였다. 4장에서는 분석 결과를 바탕으로 주요 변수의 빈도와 유사도를 분석하고, 정형 데이터 기반 모형과 비정형 데이터 통합 모형의 성능을 비교·검증하였다. 마지막으로 5장에서는 연구의 시사점과 한계, 그리고 결론을 제시하였다.
Ⅱ. 선행연구 고찰
본 장에서는 항공 수요 예측과 관련된 기존 연구를 세 가지 측면에서 검토한다. 첫째, 텍스트마이닝 기반 연구는 항공·관광 산업에서 대규모 비정형 데이터를 활용해 산업 동향, 관광객 인식, 수요 변화를 분석한 사례를 다룬다. 둘째, SNS 데이터 활용 연구는 관광지 방문 패턴, 혼잡도, 선호 속성 등을 실시간으로 파악하고 이를 예측 모형에 반영한 사례를 검토한다. 셋째, 연립방정식 모형 관련 연구는 수요·공급·가격과 같이 상호 의존적인 변수 간 구조를 분석하여 시장 메커니즘을 설명한 사례를 제시한다. 이러한 문헌 고찰을 통해, 본 연구가 다루는 정형 데이터와 비정형 데이터를 통합한 계량경제학적 항공 수요 예측 모형의 차별성과 필요성을 도출한다.
1. 텍스트마이닝과 항공수요 예측 연구
항공·관광 분야에서는 산업 동향과 관광객 인식을 파악하기 위해 설문조사, 콘텐츠 분석, 소셜 미디어 분석 등 다양한 기법이 활용되어 왔다. 그러나 전통적 방법은 조사 주기와 표본 규모의 한계로 인해 변화하는 시장 상황을 신속히 반영하기 어렵다. 이에 따라 뉴스, 블로그, SNS 등에서 생성되는 방대한 비정형 데이터를 정량적으로 분석할 수 있는 텍스트마이닝 기법이 주목받고 있다. 텍스트마이닝은 키워드 추출, 토픽 모델링, 감성 분석 등 다양한 분석 기법과 결합되어 산업 트렌드 분석과 수요 예측에 활용되며, 최근 항공·관광 분야에서도 적용 사례도 꾸준히 확대되고 있다.
Choi 등[8]은 COVID-19 팬데믹이 항공산업에 미친 영향과 동향을 분석하기 위해 네이버 뉴스 기사를 대상으로 텍스트마이닝과 토픽 모델링 기법을 적용하여 항공산업 전반의 핵심 이슈를 도출하였다. 나아가 COVID-19 전·후의 항공산업 동향과 토픽 패턴 변화를 분석하여 상황별 주요 토픽을 제시하였다. Choi[9]는 항공산업 트렌드 기반 예측 모형 설계를 목적으로 텍스트마이닝의 다양한 분석 모델을 활용해 2010년대 방법론별 주제어와 연관 키워드를 도출하고, 이를 기반으로 연간 텍스트마이닝 결과를 변수화하여 선형 회귀모형을 구축하고 성능을 검증하였다. Ko와 Lee[10]는 COVID-19 전후를 기준으로 김해공항 여행과 관련한 일반인 인식을 확인하였다. 네이버, 다음, 구글 웹에서 수집한 비정형 데이터를 정제·분석하여 COVID-19에 따른 인식 변화를 파악하고 김해공항 여행에 관한 기초자료를 도출하였다. Park 등[11]은 관광개발 및 정책 수립 시 기초자료로 활용되는 수요 예측의 정확도를 높이기 위해 온라인 검색 엔진 기반 텍스트마이닝으로 이슈 키워드를 분석하고, 특정 관광지의 수요 예측 결과를 제시하였다. 이 외에도 산업 전반에서 텍스트마이닝 기법은 수요 예측 연구에 활용되고 있다. 예를 들어 Park과 Kim[12]은 건강검진 예약 방문 고객 수를 설명하기 위해 텍스트 빈도 기반 단계적 선택법 회귀분석을 수행하였고, Hong 등[13]은 경찰 활동과 치안에 대한 국민 수요를 파악하기 위해 개방형 응답을 자동 범주화하여 주민 치안 수요 기초자료를 제시하였다. Park[14]은 실버타운 서비스의 특성을 파악하기 위해 텍스트 빈도분석을 활용하여 주요 화제와 수요를 확인하고 사회적 인식을 분석하였다.
기존 연구들은 항공·관광을 포함한 다양한 산업에서 텍스트마이닝을 활용하여 수요 예측 및 인식 분석을 수행해 왔다. 그러나 특정 국제노선, 특히 베트남과 같이 급성장하는 항공 시장을 대상으로, 정형 데이터와 비정형 데이터를 통합하여 계량경제학적 예측 모형을 설계한 연구는 미비하다.
2. SNS 데이터 활용 연구
SNS 데이터는 이용자의 행동과 선호, 사회적 관심을 실시간에 가깝게 반영할 수 있어 관광 및 항공 분야의 수요 분석에 높은 활용 가치를 지닌다. 특히 특정 관광지나 노선에 대한 온라인 반응을 분석하면, 기존 정형 데이터가 포착하지 못하는 질적 변화와 수요의 선행 신호를 확인할 수 있다. 이러한 특성으로 인해 최근 연구에서는 SNS 데이터를 활용하여 방문 패턴, 혼잡도, 선호 속성을 분석하고 이를 예측 모형에 반영하는 시도가 늘어나고 있으며, 이는 수요 예측의 정확성과 적시성을 높이는 데 기여하고 있다.
Kim 등[15]은 부산 영도를 대상으로 SNS 텍스트마이닝을 수행하여 관광객 핫플레이스를 파악하고 유형을 분석하였으며, 이를 통해 향후 관광 연계 도시재생 추진에 대한 시사점을 제시하였다. Lee 등[16]은 특정 관광지의 혼잡도 문제를 해결하기 위해 SNS 데이터를 활용한 방문자 특성 파악 및 혼잡도 예측 시스템을 제시하고, 실제 서비스와의 성능을 비교·검증하였다. Yoon 등[17]은 일본 관광 콘텐츠에 대한 중국 잠재 관광객의 관심과 선호를 분석하여 방한 관광 적용 가능성을 탐색하였으며, 중국 현지 SNS 빅데이터를 분석해 관심 특성을 도출하였다. Yun 등[18]은 관광목적지 매력 속성에 따른 북한 관광지 추천 연구를 수행했으며, SNS 기반 빅데이터 분석 솔루션을 활용하여 기초자료를 제시하였다. Lee 등[19]은 중국 관광객의 한국 개별 자유여행 인식을 분석하고, SNS 데이터를 통해 중요 가치 요소와 관광객 특성을 도출하였다. Pyo 등[20]은 동해시 관광객을 대상으로 지역관광브랜드 자산과 목적지 선택 속성을 평가하고, 블로그 데이터를 분석하여 관광지 경험 및 관련 정보를 파악하였다. Lee 등[21]은 관광분야에서 SNS 빅데이터 분석 방법을 제시하고, 실증 분석을 통해 결과를 검증하였다.
SNS 데이터는 관광·항공 수요 분석에서 효과적인 정보원을 제공하지만, 이를 항공 수요·공급·가격의 상호작용 구조에 통합하여 분석한 연구는 드물다. 특히, SNS 기반 관심도 지표를 계량경제학적 연립방정식 모형의 변수로 활용한 사례는 거의 없다.
3. 연립방정식 관련 연구
연립방정식 모형은 수요·공급·가격 등 상호 의존적인 변수 간 구조를 동시에 분석할 수 있는 계량경제학적 방법으로, 시장 메커니즘 분석과 정책 평가에 널리 활용된다. 이 접근법은 내생성 문제를 해결하면서 변수 간 인과관계를 구조적으로 파악할 수 있어, 항공·관광 산업뿐만 아니라 다양한 분야에서 예측과 시뮬레이션에 적용되고 있다. 특히 최근에는 실제 산업 데이터를 기반으로 연립방정식 모형을 구축하여 수요·공급 구조를 정량적으로 분석하고, 이를 통해 예측력과 정책 활용 가능성을 검증하는 사례가 증가하고 있다.
Pitfield 등[22]은 북대서양 장거리 시장을 대상으로 여객 수요(탑승객 수), 운항 빈도 및 기재 규모의 상호작용을 3단계 최소자승법(3SLS)으로 동시에 추정하여, 수요와 운항 전략 변수 간 양방향 인과를 검증하였다. Fu 등[23]은 미국 중·소규모 공항과 인근 허브 공항 간 ‘공항 유출(leakage)’ 현상을 고려한 수요·공급 피드백 구조를 설정하고, 대체 공항 요인이 수요와 운임·공급 변수에 미치는 영향을 2단계 최소자승법(2SLS)으로 식별하였다. Mohammadian 등[24]은 호주 국내선 시장을 대상으로 항공사의 용량결정(편수·기재 규모·탑승률)과 수요 간 상호 의존을 가정한 연립방정식을 구축하고 2SLS로 추정하여, 수요 변화에 대한 항공사의 용량 조정 메커니즘을 제시하였다. 가격 내생성 문제를 다룬 연구도 축적되고 있다. Perera 등[25]은 항공권 가격·수요 탄력성을 추정하면서 승객 흐름 기반 도구변수(IV)를 활용해 내생성을 교정하여, 미시 수준의 탄력치를 제시하였다. Mumbower 등[26]은 온라인 운임·좌석지도 데이터를 결합한 항공편 수준의 수요모형을 통해 가격 내생성에 유의한 추정 틀을 제시하였다. Hsiao 등[27]은 허브-스포크 네트워크에서 항공요금의 내생성을 해결하기 위해 도구변수(노선 거리×유가)를 적용하여 가격·수요 관계를 식별하였다. 또한 Yue 등[28]은 유럽 노선 자료로 여객 흐름과 운항 빈도 간 동시성을 고려한 고정·무작위 효과 IV 모형(FEIV/REIV)을 적용해 양방향 관계를 검증하였다.
이러한 연립방정식 접근법은 수요·공급·가격과 같은 내생변수를 동시에 추정함으로써 구조적 인과관계를 규명하는 데 강점을 지닌다. 그러나 항공 분야의 기존 연구는 대부분 정형 데이터에 기반하고 있으며, 특정 국제노선의 수요 예측을 위해 정형·비정형 데이터를 통합한 연립방정식 모형 적용 사례는 여전히 드물다. 본 연구는 이러한 공백을 메우고자 한다.
항공·관광 분야에서는 텍스트마이닝과 SNS 데이터를 활용하여 산업 동향과 수요 변화를 분석하는 연구가 점차 확대되고 있으며, 연립방정식 모형을 적용해 수요·공급·가격 간 상호작용을 분석하는 사례도 다수 보고되고 있다. 그러나 기존 연구들은 대체로 정형 데이터 또는 비정형 데이터 중 한 가지 유형에만 국한되거나 특정 변수에 집중하는 경향이 있었다. 특정 국제노선을 대상으로 정형·비정형 데이터를 통합하고, 이를 연립방정식 모형과 같은 계량경제학적 방법에 적용하여 수요·공급·가격 구조를 동시에 분석한 사례는 매우 드물다. 이에 본 연구는 한국–베트남 노선을 대상으로 정형·비정형 데이터를 결합한 연립방정식 기반 수요 예측 모형을 구축함으로써 기존 연구의 한계를 보완하고, 학문적·실무적 시사점을 제시하고자 한다.
Ⅲ. 연구 방법론
1. 연구의 접근 방법
본 연구는 정형 데이터와 비정형 데이터를 결합하여 한국-베트남 노선의 수요 변화를 구조적으로 분석하고자 한다. 이를 위해 2015–2024년 기간의 연도별 노선 데이터를 수집·통합하였으며, 데이터는 크게 세 범주로 구분된다. 첫째, 여객 수요, 운항 편수, 유가(Brent), 환율(원/달러), 실질 GDP 등 정형 변수를 활용하여 시장의 기본 구조를 정량화하였다. 평균운임지수(SPI)는 Brent, KRW/USD, 운항편수의 역수를 표준화한 후 주성분 분석(PCA)을 통해 통합 지표로 산출하고, 2019년을 기준(100)으로 지수화하여 산정하였다. 둘째, 텍스트마이닝 기법을 통해 온라인 뉴스·SNS 데이터에서 주요 키워드와 토픽을 분석하고, 이를 통합하여 온라인 관심도 지표(OnlineIndex)로 변환하였다. 셋째, 팬데믹 여부 등 외부 충격 변수를 포함하여 수요와 가격의 변동 요인을 모형에 반영하였다.
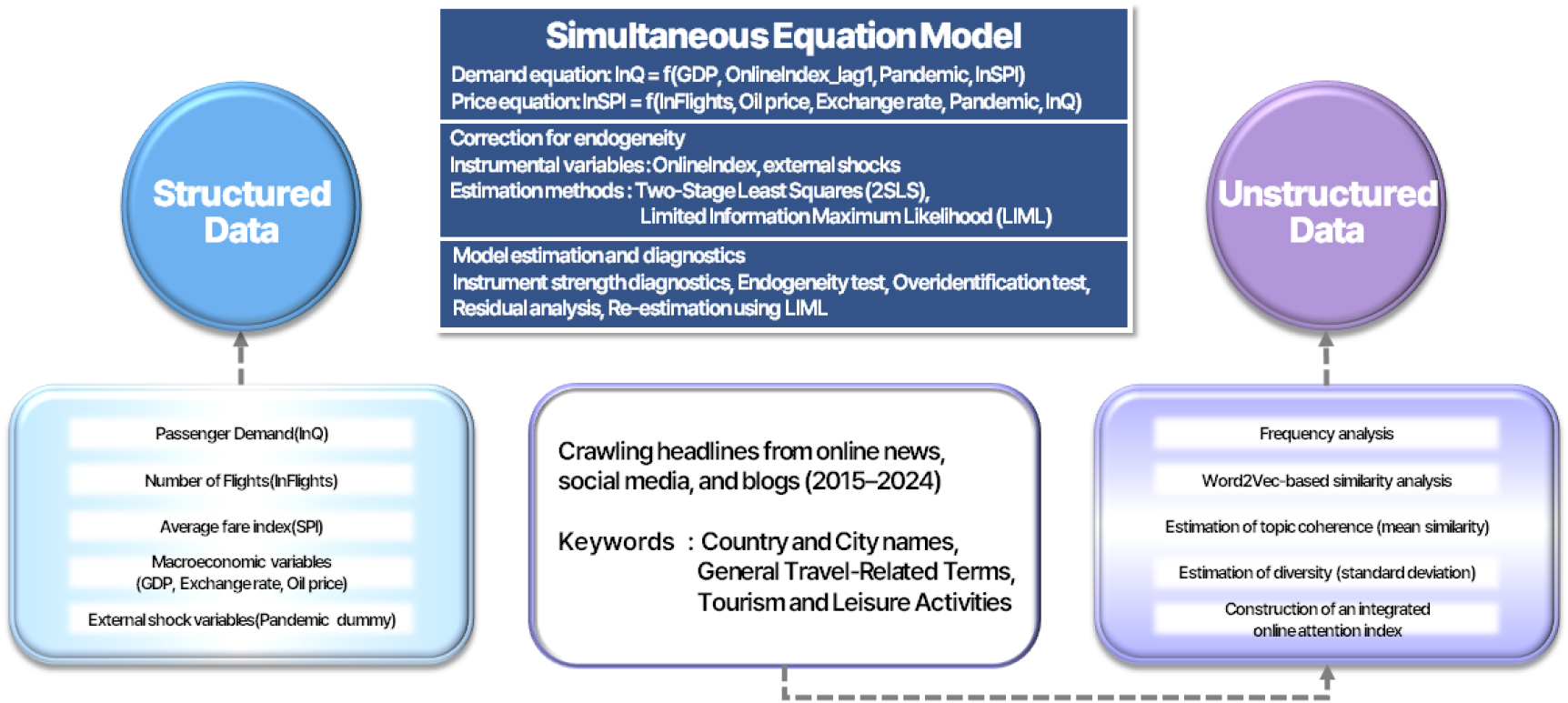
분석 절차는 다음과 같다. 먼저, 수집된 모든 데이터에 대해 결측치를 점검하고, 이상치를 제거한 뒤 로그 변환 등을 적용하여 분석의 신뢰성을 확보하였다. 다음으로, 비정형 데이터는 연도별 주요 키워드 빈도와 Word2Vec 기반 평균 유사도를 결합하여 지수화하였다. 마지막으로, 수요와 가격 간 상호작용과 내생성 문제를 반영하기 위해 연립방정식 모형을 설정하고, 2단계 최소자승법(2SLS)을 적용하여 계수를 추정하였다. 이러한 접근은 단일 회귀분석이 간과하는 시장 구조의 상호 의존성을 고려할 수 있다는 점에서 유효하다. 본 연구의 최종변수정의는 Table 1과 같으며 전체 분석 절차는 Fig. 1과 같다.
Table 1.
Definitions of Final Variables
2. 텍스트마이닝
뉴스·SNS·블로그 등 비정형 텍스트에서 관심 지표를 추출·정량화하는 과정이다. 텍스트마이닝 기법을 통하여 주요 키워드와 토픽을 추출하고, 분석 과정에서 설명변수로 활용할 수 있도록 구조화한다. 본 연구에서 비정형 텍스트 처리 과정은 크롤링, 단순 빈도분석, Word2Vec 유사도 분석 절차로 진행한다.
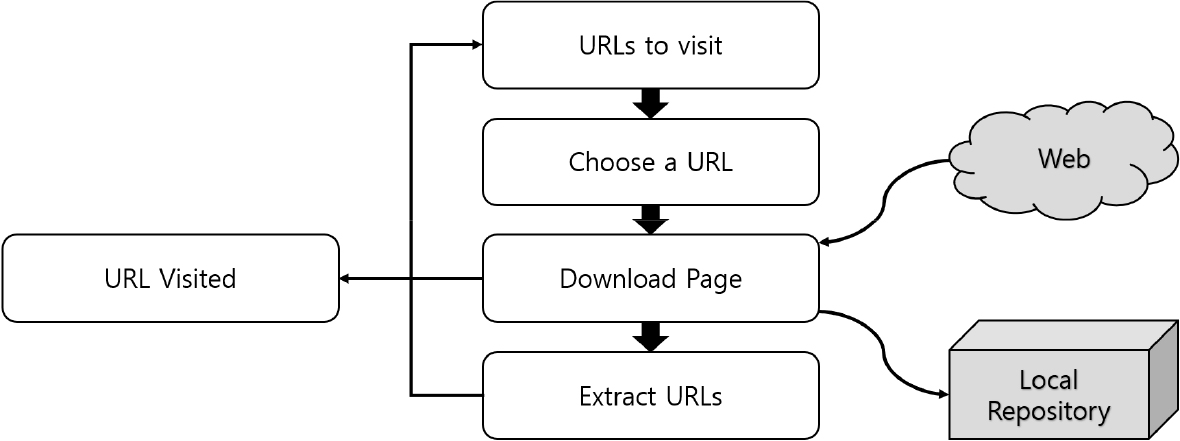
뉴스·SNS·블로그 등 분산된 웹 문서에서 관심 신호를 안정적으로 수집하기 위해 크롤링 기법을 활용한다. 웹 크롤링은 시드 URL 집합에서 하이퍼링크를 따라가며 다운로드-파싱-추출을 반복하는 과정으로, 대규모 검색·수집 시스템에서 표준적으로 사용되는 방법이다. 본 연구에서는 노선·도시·관광 키워드로 도메인 화이트리스트를 구성하여 시드를 확보하며, 도메인별 동시연결 한도와 대기시간을 설정하여 서버 부하를 회피한다. 최종적으로 HTML을 수집한 후 본문을 추출하고, 언어·인코딩 정규화 및 중복 제거 과정을 거쳐 메타 데이터를 저장한다. Fig. 2는 웹 크롤러의 기본 구조를 나타낸다[29].
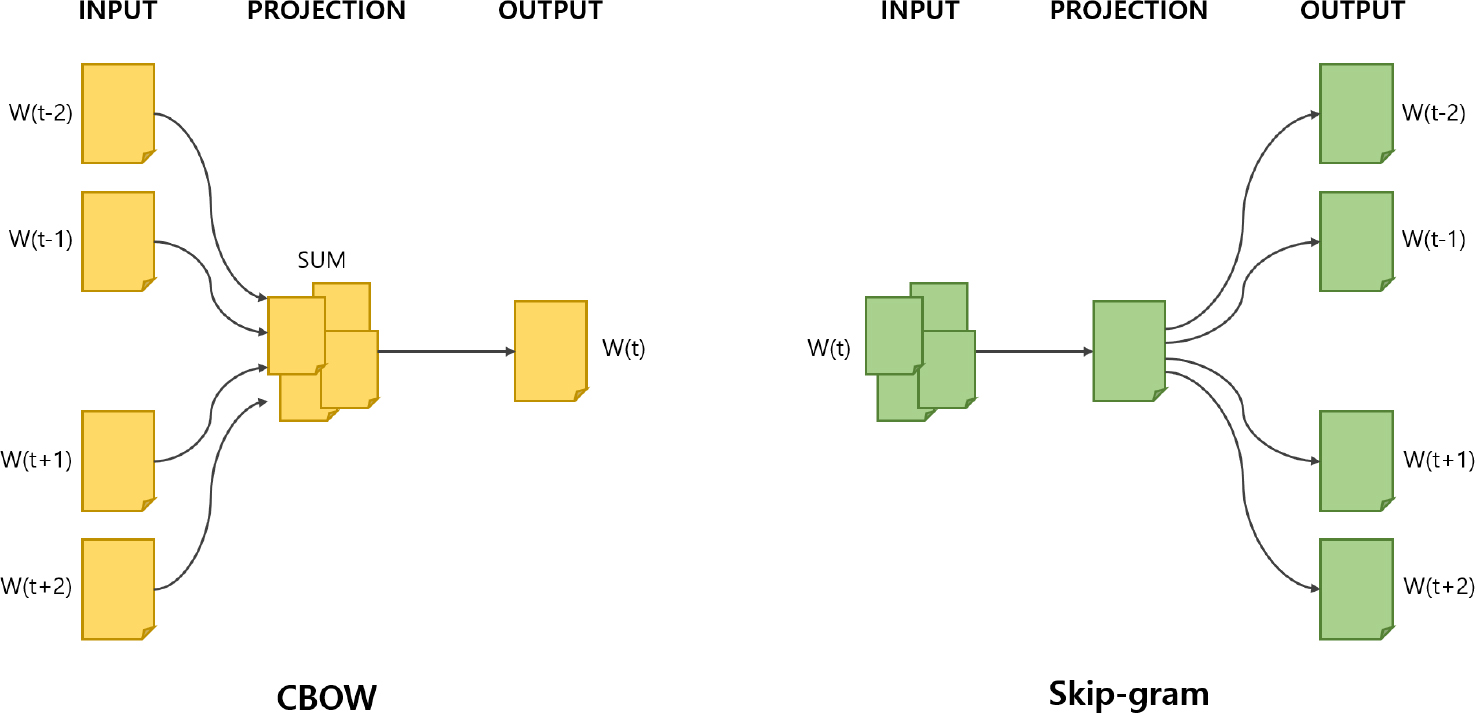
표현이 다른 동의·연관 어휘를 연속 벡터 공간에서 의미적으로 가깝게 배치하여 관심 주제의 변화를 안정적으로 포착하기 위해 Word2Vec 기법을 활용한다. 문맥에서의 공동 출현 패턴을 학습해 어휘를 연속 벡터로 변환하는 방식이며, 중심어를 예측하는 CBOW (Continuous Bag Of Word)와 중심어를 통해 문맥을 예측하는 Skip-gram 두 형태가 대표적이다. 이렇게 학습된 벡터는 코사인 유사도 등의 과정을 통해 의미 유사성을 정량화한다. Fig. 3은 Word2Vec의 두 가지 대표 학습 방식인 CBOW와 Skip-gram의 작동 원리를 나타낸다[30].
연도별 노선 단위에서 온라인 관심의 규모와 급등·급락을 신속하고 명료하게 파악하기 위해 단순 빈도분석을 활용한다. 단순 빈도분석은 수집된 비정형 텍스트를 토큰화한 뒤, 핵심 어휘의 등장 횟수를 집계하여 관심의 크기와 변동을 확인하는 절차이다. 한글·영문 혼용을 정규화하고 불용어를 제거한 뒤, 형태소 기반 토큰화를 수행한다. 뉴스·블로그 자료는 해시태그 분리, 이모지·특수문자 제거, 중복·광고 글 필터링 등의 과정을 거친다. 전처리된 온라인 기사 데이터에서 연도별 노선 단위로 단어의 출현 횟수와 상대 비중을 확인하여 주요 이슈의 급등·급락을 파악한다[31].
연도별 노선 단위 텍스트에서 추출한 지표가 관심 주제와 얼마나 가까운지를 정량화하여 이슈의 확산·전이·급변을 파악하기 위해 유사도 분석을 실시한다. 이는 문서에서 의미 벡터와 기준 주제 벡터 사이의 근접도를 계산하는 절차로, Word2Vec 기법으로 수집한 임베딩을 활용한다. 코사인 유사도를 기본 지표로 사용하며, 벡터의 길이 영향을 배제하고 내용 구성의 유사성만을 평가한다. 식 (1)은 두 의미 벡터 x와 y 간의 코사인 유사도를 계산하는 식으로, 값이 1에 가까울수록 의미적으로 유사함을 나타낸다[32].
Word2Vec 임베딩과 같이 고차원 의미 벡터를 직관적으로 해석하고, 유사 주제 간 군집 구조를 시각적으로 파악하기 위해 t-SNE (t-distributed Stochastic Neighbor Embedding) 분석을 수행한다. 이 기법은 다차원 공간에서의 벡터 간 근접성을 2차원 또는 3차원 평면에 최대한 유지하여 주제 간 의미적 유사성과 변화 패턴을 탐색할 수 있게 한다. t-SNE는 비선형 차원 축소 기법으로 고차원 데이터의 인접 관계 보존에 중점을 둔다. 식 (2), (3)은 각각 고차원과 저차원 공간에서 점 , 간 조건부 확률을 계산하는 식이며[33], 식 (4)는 고차원 확률 분포 와 저차원 확률 분포 간 Kullback–Leibler 발산을 계산하는 식이다. t-SNE는 이 발산을 최소화하도록 학습하며, 확률 분포의 꼬리 부분에 t-분포를 적용해 crowding 문제를 완화한다[33].
본 연구에서는 온라인 뉴스 기사 헤드라인을 기반으로 산출한 연도별 키워드 빈도와 Word2Vec 기반 의미 유사도를 활용하여, 베트남 여행 관련 온라인 관심도를 계량화한 지표를 구축하였다. 지표화 과정은 다음과 같다.
먼저, 분석 대상 주제군(Topic set)을 정의하였다. 주제군 선정의 객관성을 확보하기 위해 1차적으로 전체 뉴스 데이터의 빈도 분석을 통해 상위 100개 단어를 추출하였으며, 이 중 여행 수요와 직결되는 목적지, 활동, 상품 관련 핵심어와 선행연구에서 활용된 관광 키워드를 교차 검토하여 최종 주제어 집합을 확정하였다[8]. 주제군은 구체적으로 국가 및 도시명(‘베트남’, ‘다낭’, ‘나트랑’, ‘하노이’, ‘호치민’), 여행 일반(‘여행’, ‘관광’, ‘패키지’, ‘항공권’, ‘여행사’), 관광·여가 활동(‘리조트’, ‘골프’, ‘호텔’, ‘투어’)으로 구성하였다. 주제군 키워드의 연도별 빈도 합을 전체 키워드 빈도 합으로 나누어 관심도의 상대적 규모를 나타내는 규모 지표(FreqIndex)를 산출하였으며, 산출식은 식 (5)와 같다[34].
주제 일관성과 다양성을 평가하기 위해 Word2Vec 모델을 연도별 코퍼스에 학습시킨 후, 상위 키워드 간 코사인 유사도를 계산하였다. 이때 평균값(W2V_mean)은 주제 일관성 지표로, 표준편차(W2V_std)는 주제 다양성의 역지표로 정의하였다. 산출된 지표들을 표준화(z-score)한 뒤, 이를 결합하여 온라인 관심도 지표(OnlineIndex)를 구성하였으며, 결합 방식은 식 (6)과 같다[35].
3. 연립 방정식
본 연구는 수요–가격의 두 구조식을 동시에 설정하고, 외생적 시프트 변수인 온라인 관심도 지표를 도구변수로 활용하여 2단계 최소자승법(2SLS)과 제한정보최대우도법(LIML)으로 계수를 추정하였다. 이는 한국–베트남 노선의 여객 수요()와 가격지수()가 동일 기간에 상호작용하는 내생적 관계에 있으며, 단일 방정식 추정만으로는 가격과 수요의 역인과성(endogeneity)을 동시에 통제하기 어려움에 기인한다[36]. 이러한 접근은 전통적 설명변수만으로는 반영하기 어려운 단기 수요 변동을 충분히 제어할 수 있다는 장점을 지닌다[37].
분석 단위는 2016–2024년 연도별 시계열이며, 내생변수는 여객 수요()와 가격지수()이다. 수요식에는 실질 GDP (), 1기 시차의 온라인 관심도 지표(), 팬데믹 여부()를 외생 변수로 포함하고, 가격지수()를 내생변수로 설정하였다. 특히 1기 시차의 온라인 관심도 지표를 사용한 이유는 다음과 같다. 일반적으로 사람들이 특정 여행지에 대해 온라인으로 검색하거나 뉴스를 접하는 ‘관심’이 먼저 발생하고, 이 관심이 실제 ‘여행’ 행동으로 이어지기까지 시간이 걸린다고 보았다. 즉, 2023년 베트남 여행에 대한 관심이 높았다면, 그 영향이 2024년 항공 수요로 나타날 것이라고 가정하였다. 가격식에는 운항편수(), 유가(), 환율(), 팬데믹 여부()를 외생 변수로 포함하고, 여객 수요()를 내생변수로 설정하였다. 다음 식 (7), (8)은 각각 수요식과 가격식을 나타낸다[38].
내생성 문제를 해결하기 위해 1단계에서 각 내생변수를 해당 식에서 배제된 외생변수로 예측한 후, 2단계에서 예측치를 구조식에 대입하여 계수를 추정하였다. 1단계 회귀식은 식 (9), (10)과 같다[39].
이 예측치를 사용하여 수요식과 가격식의 내생변수 자리에 대입한 뒤, 2단계에서 OLS로 계수를 추정한다. 추정 시 표본 수가 작고 약한 도구 가능성이 존재할 수 있으므로 2SLS와 함께 LIML을 병행하여 추정 안정성을 비교·검증하였다. 모형 추정 후 도구변수의 적합성과 식별력을 확보하기 위해 다음과 같은 진단 절차를 적용하였다. 첫째, 도구변수 강도 검정을 위해 1단계 회귀의 공동 F-통계량과 partial R2값을 산출하고, Staiger–Stock (1997)의 기준치(10 이상)와 비교하였다. 둘째, 내생성 검정에는 Durbin–Wu–Hausman (DWH) 검정을 사용하여 OLS와 IV 추정치 간 차이가 통계적으로 유의한지 평가하였다. 셋째, 과식별 제약 검정에는 Sargan 검정 또는 Hansen J 검정을 적용하여 과잉 식별된 도구변수 집합의 타당성을 검증하였다. 넷째, 잔차 특성 진단으로 Breusch–Pagan 검정(이분산성), Durbin–Watson 통계량(자기상관), Shapiro–Wilk 검정(정규성)을 수행하였다. 마지막으로, 약한 도구 강건성 검정을 위해 LIML 추정치와 Anderson–Rubin 검정을 병행하여 도구변수의 식별력과 결과의 강건성을 확인하였다.
Ⅳ. 연구 결과
1. 텍스트마이닝
1) 전체 빈도분석
본 연구에서는 ‘베트남 여행’을 중심 키워드로 설정하고, 2015년부터 2024년까지의 온라인 뉴스 기사 헤드라인을 수집하여 연도별 빈도분석을 수행하였다. 수집 과정에서 중복 문서를 제거하고, 특수문자·HTML 태그 등 불필요 요소를 삭제한 뒤, 형태소 분석과 불용어 제거를 거쳐 데이터를 정제하였다. 이러한 절차를 통해 데이터 왜곡을 최소화하여 분석의 신뢰성을 확보하였다.
(1) 팬데믹 이전(2015–2019년)
팬데믹 이전(2015–2019년)에는 ‘베트남’과 ‘여행’이 전 기간 최상위를 차지하며 해당 노선의 안정적 인기와 높은 관심도를 반영하였다. 2015년에는 ‘여행’이 746회, ‘베트남’이 668회로 압도적인 빈도를 보였고, ‘다낭’, ‘관광’, ‘여행지’ 등 관광지 및 일반 관광 관련 키워드가 다수 상위권에 포함되었다. 2017–2019년에는 ‘패키지’, ‘투어’, ‘항공’ 등 여행 상품·서비스 관련 단어가 두드러졌으며, 2018년의 ‘박항서’, 2019년의 ‘나트랑’처럼 특정 인물이나 신규 인기 관광지가 일시적으로 주목받는 현상도 나타났다. 이는 당시 스포츠 교류, 신규 노선 개설, 마케팅 이벤트 등 외부 요인이 관심 변화를 촉발한 사례로 해석된다. 팬데믹 이전 연도별 빈도분석 상위 10개 결과는 Table 2와 같다.
Table 2.
Top 10 Results of Year-by-Year Frequency Analysis (2015-2019)
(2) 팬데믹 시기(2020–2021년)
팬데믹 시기(2020–2021년)에는 키워드 구성이 크게 변화하였다. ‘베트남’, ‘여행’이 여전히 상위를 차지했지만, ‘코로나’, ‘백신’, ‘재개’ 등 감염병 및 방역 관련 키워드가 새롭게 상위 10위권에 진입하였다. 2020년 ‘코로나’는 236회로 세 번째 높은 빈도를 기록했으며, 2021년에도 ‘코로나’ (128회), ‘백신’ (56회)이 상위권에 포함되었다. 이 시기에는 ‘세계’, ‘의료’, ‘업계’와 같이 여행 목적과 직접 관련 없는 단어도 빈번하게 등장했는데, 이는 팬데믹이 여행 산업 전반의 담론 구조를 변화시켰음을 보여준다. 팬데믹 시기 연도별 빈도분석 상위 10개 결과는 Table 3과 같다.
Table 3.
Top 10 Results of Year-by-Year Frequency Analysis (2020–2021)
(3) 팬데믹 이후(2022–2024년)
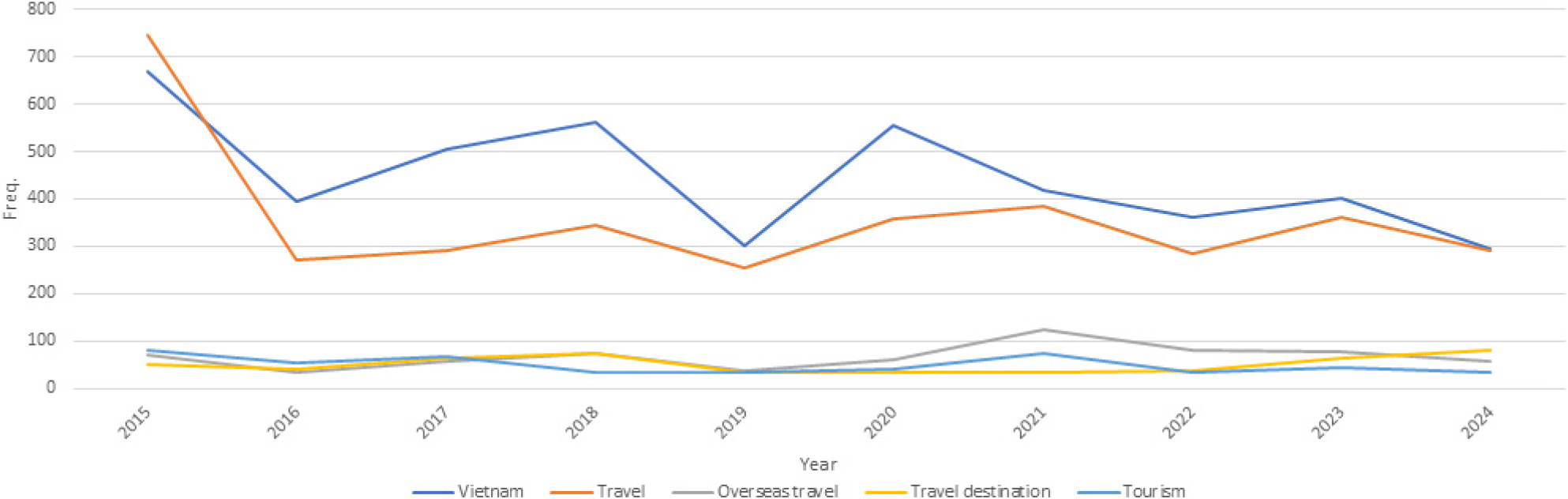
팬데믹 이후(2022–2024년)에는 키워드 구조가 다시금 관광·여행 중심으로 회귀하였다. ‘여행지’, ‘패키지’, ‘상품’ 등이 상위권에 복귀하였으며, ‘일본’, ‘제주항공’, ‘연말’, ‘트렌드’ 등 경쟁 여행지·항공사 브랜드·여행 시즌을 나타내는 키워드가 다수 포함되었다. 특히 2023년 ‘제주항공’ (52회)과 ‘연말’ (48회)의 상위권 진입은 저비용항공사의 노선 확대와 시즌별 마케팅이 관심도를 끌어올린 사례로 해석된다. 2024년에는 ‘트렌드’, ‘내년’과 같이 미래 전망을 시사하는 키워드가 등장하며, 단기 여행뿐 아니라 향후 여행 계획 및 수요 변화에 대한 관심이 확대되고 있음을 시사한다. 팬데믹 이후 연도별 빈도분석 상위 10개 결과는 Table 4와 같으며, 연도별 상위 5개 핵심 키워드의 빈도 변화를 시각화한 결과는 Fig. 4와 같다.
Table 4.
Top 10 Results of Year-by-Year Frequency Analysis (2022–2024)
2) Word2Vec 유사도 분석
Word2Vec 유사도 분석은 각 연도별로 ‘베트남 여행’과 의미적 유사도가 높은 상위 10개 단어를 도출하여, 시기별 연관어 구조 변화를 확인하였다. 이를 통해 단순 빈도 기반 분석에서 포착되지 않는 연관성과 맥락 변화를 규명하고, 시기별 여행 수요 특성을 해석하였다. 본 분석에서 도출된 코사인 유사도(Cosine Similarity) 값은 0–1 사이의 값을 가지며, 1에 가까울수록 뉴스 텍스트 내에서 ‘베트남 여행’과 문맥적 결합도가 강함을 의미한다. 일반적으로 사회과학 텍스트 분석에서 0.5 이상의 유사도는 매우 강한 연관성을 시사한다. 도출된 상위 10개 단어는 무작위적인 단어가 아니라, 해당 시기 여행객의 목적(골프, 휴양)과 제약(코로나, 백신)을 구체적으로 설명하는 적합한 단어들로 구성되어 있어 분석의 타당성을 뒷받침한다.
(1) 팬데믹 이전(2015–2019년)
분석 결과, 팬데믹 이전 시기에는 ‘여행지’, ‘해외여행’, ‘다낭’, ‘여행객’, ‘패키지’, ‘골프’, ‘리조트’ 등 여행 목적지와 상품을 직접적으로 지칭하는 단어가 상위 유사어로 도출되었다. 특히 ‘다낭’과 같은 특정 해외 목적지, ‘골프’, ‘리조트’와 같이 레저·휴양 활동을 나타내는 단어들이 함께 나타나 해당 시기 해외여행 수요가 휴양·레저 중심이었음을 시사한다. 특히 2016년의 ‘해외여행’ (0.626)과 2017년의 ‘다낭’ (0.587)은 0.5를 상회하는 높은 코사인 유사도 값을 기록하였는데, 이는 당시 온라인 뉴스 담론 내에서 ‘베트남 여행’이라는 키워드가 특정 목적지 및 일반적인 해외여행 트렌드와 매우 강력하고 일관된 의미적 결합(Semantic Cohesion)을 형성하고 있었음을 정량적으로 보여준다. 또한 ‘여행사’, ‘하나투어’와 같이 산업 주체를 나타내는 단어가 다수 포함되어 여행상품 유통망이 활발했음을 알 수 있다. ‘가족’, ‘연휴’와 같이 동반자, 여행 시기를 나타내는 단어의 출현은 가족 단위 패키지여행과 특정 휴가 시즌 중심의 수요 패턴이 두드러졌음을 보여준다. 전반적으로 팬데믹 이전에는 경제·사회적 제약이 적어 여행 담론이 목적지·상품 중심으로 구성되고, 여가·소비 경험 확장을 강조하는 경향이 뚜렷했다. 팬데믹 이전 연도별 Word2Vec 유사도 분석 상위 10개 결과는 Table 5와 같다.
Table 5.
Top 10 Results of Word2Vec Similarity Analysis (2015–2019)
(2) 팬데믹 시기(2020–2021년)
팬데믹 시기에는 ‘코로나’, ‘신종’, ‘백신’, ‘오미크론’ 등 감염병 및 방역 관련 용어가 상위 유사어로 등장하며, 해외여행 수요와 관련된 담론이 외부 충격 요인에 의해 강하게 제약받았음을 보여준다. 동시에 ‘해외여행’, ‘여행객’, ‘여행지’, ‘여행사’, ‘항공’ 등 여행 관련 핵심 단어들도 여전히 나타났으나, 팬데믹 이전에 비해 전반적인 유사도 값이 하락하여 관심과 연결성이 약화된 모습을 보였다. 실제로 상위 연관어들의 평균 유사도는 팬데믹 이전 대비 현저히 낮아진 0.3–0.4대 수준(ex: 2020년 ‘코로나’ 0.360, 2021년 ‘백신’ 0.330)에 머물렀다. 이러한 수치적 하락은 여행에 대한 사회적 관심이 특정 주제로 응집되지 못하고, 방역이나 제한 조치와 같은 외부 충격 요인에 의해 담론 구조가 파편화(Fragmentation)되었음을 의미한다. ‘위드’, ‘동남아’, ‘아시아’ 등 일부 단어는 이동 재개 가능성에 대한 기대감을 반영하며, 제한적인 국제 이동과 특정 지역 중심의 회복 기대가 형성되었음을 시사한다. 특히, ‘아시아’, ‘동남아’와 같은 지역명은 장거리 여행보다 근거리·단거리 국제선에 대한 관심이 상대적으로 높아졌음을 의미한다. 이 시기 여행 담론은 목적지·활동보다는 감염병 상황, 방역 조치, 이동 제한과 같은 외생적 변수에 더 큰 영향을 받으며 형성되었다. 팬데믹 이전 연도별 Word2Vec 유사도 분석 상위 10개 결과는 Table 6과 같다.
Table 6.
Top 10 Results of Word2Vec Similarity Analysis (2020–2021)
(3) 팬데믹 이후(2022–2024년)
팬데믹 이후 시기에는 ‘해외여행’, ‘여행객’, ‘여행지’, ‘관광’ 등 여행 활동을 직접적으로 나타내는 핵심어가 상위권에 재등장하며, 억눌렸던 해외여행 수요가 본격적으로 회복되고 있음을 확인할 수 있다. 수치적으로도 2023년 ‘여행지’ (0.531), 2024년 ‘해외여행’ (0.560)과 ‘여행객’ (0.560) 등의 유사도가 다시 팬데믹 이전 수준인 0.5대 이상으로 회복되는 경향을 보였다. 이는 베트남 여행에 대한 대중의 인식이 불확실성을 벗어나, 다시금 명확한 여행 목적성과 강한 연관성을 갖춘 담론 구조로 복귀했음을 시사한다. ‘선호’, ‘내년’, ‘트렌드’와 같은 단어는 향후 여행 계획과 수요 전망에 대한 관심이 커졌음을 보여주며, 이는 중장기적으로 여행 수요 예측에 중요한 변수로 작용할 가능성이 있다. 또한 ‘골프’, ‘달랏’, ‘중국’ 등은 팬데믹 이전과 유사하게 특정 목적지·테마 중심의 여행 패턴이 재부상하고 있음을 시사한다. 이와 함께 ‘급증’, ‘연말’과 같은 계절·시기성을 나타내는 단어들은 특정 시점에 집중되는 수요 변화가 존재함을 의미하며, 이는 마케팅 및 항공편 운항 계획 수립 시 중요한 고려사항이 된다. 전반적으로 팬데믹 이후의 연관어들은 여행 수요가 회복기에 접어들었을 뿐 아니라, 여행 목적·형태의 다양화와 특정 시기 수요 집중 현상이 동시에 나타나는 특징을 보여준다. 팬데믹 이후 연도별 Word2Vec 유사도 분석 상위 10개 결과는 Table 7과 같다.
Table 7.
Top 10 Results of Word2Vec Similarity Analysis (2022-2024)
3) 비정형 데이터 지표화
규모 지표(FreqIndex)는 2017년이 0.222로 가장 높게 나타나, 해당 연도에 주제군 키워드의 상대적 빈도 비중이 최대였음을 보여준다. 이는 저비용항공사 신규 취항, 박항서 감독 부임, 관광 수요 증가 등이 복합적으로 작용한 시기와 일치한다. 주제 일관성 지표(W2V_mean)는 2019년(0.544)과 2017년(0.540)에서 높게 나타나, 해당 시기 온라인 담론이 특정 주제를 중심으로 응집되었음을 시사한다. 반면 주제 다양성의 역지표인 W2V_std는 2016년(0.090)과 2021년(0.071)에서 높아, 해당 연도에는 다양한 연관 주제가 혼재되어 있었음을 확인하였다. 종합 지표(OnlineIndex)는 2017년이 2.126으로 최대, 2021년이 -2.801로 최소를 기록하였다. 즉, 2017년은 베트남 여행에 대한 온라인 관심이 규모와 일관성 측면에서 모두 높았던 반면, 2021년은 COVID-19 팬데믹과 여행 제한 조치로 관심도가 크게 저하되었음을 보여준다. 연도별 비정형 데이터 지표는 Table 8과 같다.
Table 8.
Year-by-Year Unstructured Data Indicators
2. 연립방정식
본 연구는 한국-베트남 노선의 수요·가격 간 상호작용을 구조적으로 반영하기 위하여 2개식 구조식으로 구성된 연립방정식 모형을 설정하였다. 내생성 문제를 해결하기 위해 2단계 최소자승법(2SLS)을 적용하였다. 수요식에는 실질 GDP, 1기 시차의 온라인 관심도, 팬데믹 여부를 외생 변수로 포함하고, 가격지수(SPI)를 내생변수로 설정하였다. 가격식에서는 운항 편수(공급), 유가, 환율, 팬데믹 여부를 외생 변수로, 여객 수요를 내생변수로 포함하였다. 분석 대상 기간은 2015–2024년으로, 전처리 과정에서 결측치와 이상치를 제거하였다.
1) 수요식 추정 결과
수요식의 결정계수()는 0.667로, 모형이 약 66.7%의 설명력을 가지는 것으로 나타났다. 실질 GDP의 계수는 5.048 (p = 0.0015)로 통계적으로 유의하며, GDP 증가가 여객 수요를 유의하게 증가시키는 것으로 분석되었다. 팬데믹 더미 변수는 –2.584 (p = 0.0334)로 유의한 음(-)의 영향을 보여, 팬데믹 기간동안 수요가 급감했음을 시사한다. 반면, 가격지수(SPI)의 계수는 –0.057 (p = 0.5069)로 음(-)의 방향성이 관찰되었으나 통계적으로 유의하지 않았다. 온라인 관심도(1기 시차) 역시 p = 0.7288로 통계적 유의성을 확보하지 못했다. 해당 계수가 음(-)의 부호를 보인 것은 경제적 인과관계라기보다는, 연간 데이터(n = 9) 사용에 따른 자유도 부족과 팬데믹 더미 변수(Shock)가 수요 급감의 대부분을 설명함에 따라 발생한 추정상의 한계(Noise)로 해석된다. 즉, 1단계 추정에서 확인된 바와 같이 약한 도구변수 문제로 인해 계수의 추정치가 불안정하게 도출된 결과로 판단된다. 연립방정식(2SLS) 중 수요식의 추정 결과는 Table 9와 같다.
Table 9.
Estimation Results for the Demand Equation in the Simultaneous Equations Model (2SLS)
2) 가격식 추정 결과
가격식의 결정계수(R2)는 0.900으로, 모형이 높은 설명력을 보였다. 공급(운항편수)의 계수는 –14.564 (p < 0.001)로, 공급 확대가 가격지수를 유의하게 하락시키는 것으로 나타났다. 유가는 21.824 (p < 0.001)로, 연료비 상승이 가격 인상 압력으로 작용함을 보여준다. 팬데믹 더미는 –14.529 (p < 0.001)로, 팬데믹 기간에 가격지수가 급락하였음을 확인하였다. 여객 수요의 계수는 2.4811 (p = 0.0004)로 유의한 양(+)의 영향을 보여, 수요 증가가 가격 상승으로 이어지는 경향을 나타냈다. 환율은 유의하지 않았다(p = 0.8121). 연립방정식(2SLS) 중 가격식 추정 결과는 Table 10과 같다.
Table 10.
Estimation Results for the Price Equation in the Simultaneous Equations Model (2SLS)
3) 도구변수 진단
2단계 최소자승법(2SLS) 모형의 적합성과 도구변수의 타당성을 평가하기 위해 도구변수 강도, 내생성, 과식별 제약, 잔차 특성에 대한 검정을 수행하였다. 1단계 회귀의 공동 F-통계량은 수요식 4.282, 가격식 5.485로 Staiger–Stock (1997) 기준치인 10을 하회하여 두 식 모두 약한 도구(weak instrument) 가능성이 존재하였다. partial R2 값은 각각 0.865와 0.846으로 외생 변수에 대한 도구변수의 관련성은 높은 편이지만, 표본 수(n = 9)가 작아 식별력이 제한되는 것으로 해석된다. DWH 검정 결과, 수요식은 p = 0.845로 내생성이 통계적으로 유의하지 않았으며, 가격식은 p = 0.074로 10% 수준에서 경계선상의 유의성을 보였다. Sargan 과식별 검정에서는 수요식이 p = 0.012로 귀무가설이 기각되어 도구변수 유효성에 한계가 있는 것으로 나타났으며, 가격식은 p = 0.296으로 유효성이 유지되었다.
잔차 진단 결과, Breusch–Pagan (BP) 검정에서 수요식은 p = 0.093으로 10% 수준에서 이분산성이 일부 의심되었고, 가격식은 p = 0.244로 유의하지 않았다. Durbin–Watson (DW) 통계량은 두 식 모두 약 3.11–3.14로 2보다 높아 음의 자기상관 가능성이 있으나, 표본 수가 매우 작아 해석에 주의가 필요하다. Shapiro–Wilk 정규성 검정에서는 두 식 모두 p > 0.05로 잔차 정규성이 유지되었다.
또한, 약한 도구 가능성을 보완적으로 검토하기 위해 제한정보 최대우도법(LIML)으로 재추정한 결과, 수요식의 Kappa 값은 6.774, 가격식의 Kappa 값은 1.135로 나타나, 특히 가격식에서 도구변수 강도가 매우 약함을 확인하였다. Anderson–Rubin 검정에서도 수요식은 p = 0.0002로 귀무가설이 기각되어 식별 문제 가능성이 시사되었다. 이러한 결과는 표본 수가 매우 제한적인 상황에서 도구변수의 강도 부족과 과식별 문제를 동시에 고려해야 함을 의미한다. 도구변수 및 잔차 진단 결과는 Table 11과 같다.
Table 11.
Instrument Strength and Diagnostic Test Results
Ⅴ. 결론
본 연구는 한국-베트남 노선을 대상으로, 정형 데이터(운임, 공급 좌석 수, 거시경제 지표 등)와 비정형 데이터(온라인 관심도 지표)를 결합하여 계량경제학적 수요 예측 모형을 구축하였다. 이를 통해 가격·공급·외부 충격 및 사회적 관심도가 수요에 미치는 영향을 분석하였다. 분석 과정에서는 수요와 가격 간 내생성을 통제하기 위해 연립방정식 모형을 적용하였으며, 2단계 최소자승법(2SLS)과 제한정보최우추정법(LIML)을 병행하여 추정 결과를 비교·검증하였다.
분석 결과, 정형 데이터 기반의 주요 변수들은 시장 구조를 일관되게 설명하였다. 수요식에서는 실질 GDP가 유의한 양(+)의 영향을 미쳐 거시경제 성장과 국제선 수요가 밀접하게 연동됨을 확인하였다. 가격식에서는 항공편 수(공급)가 유의한 음(-)의 영향을, 유가와 외부 충격 변수는 유의한 양(+)의 영향을 미쳐 시장 구조와 비용 요인이 항공 운임 결정에 강하게 작용함을 입증하였다.
그러나 본 연구는 통계적 추정 과정에서 명확한 한계를 갖는다. 가장 근본적인 한계는 2015–2024년의 연간 데이터를 사용함에 따라 표본 수가 9개(n = 9)로 절대적으로 부족하다는 점이다. 이러한 소표본 문제는 2단계 최소자승법(2SLS) 추정의 신뢰성을 담보하는데 제약으로 작용했다. 1단계 회귀의 공동 F-통계량이 Staiger–Stock 기준치(10)에 미달하여(수요식 4.282, 가격식 5.485) ‘약한 도구(weak instrument)’ 문제가 발생했음을 확인하였다.
약한 도구변수 환경에서는 추정된 계수 자체의 신뢰도가 저하될 수 있으며, 이는 본 연구가 핵심적으로 검증하고자 한 ‘온라인 관심도 지표’가 통계적 유의성을 확보하지 못한 직접적인 원인으로 해석된다. 나아가, 소표본 환경은 Sargan 과식별 검정(수요식 p = 0.012), 잔차의 이분산성 의심(BP p = 0.093) 및 자기상관 가능성(DW 3.11–3.14) 등 각종 통계적 진단 테스트 결과의 신뢰성마저 저하시켜, 모형의 견고성을 명확히 입증하는 데 한계가 있었다. LIML을 통한 재추정에서도 유의성은 여전히 제한적이었다.
따라서 본 연구가 제시한 계수 값들은 이러한 소표본 및 약한 도구변수 문제라는 통계적 한계로 인해 그 유의성과 크기를 해석하는 데 각별한 주의가 필요하다. 향후 연구에서는 표본 기간 확대, 패널 데이터 활용, 비정형 데이터의 시차 구조 최적화 등을 통해 모형의 예측 성능과 추정 일관성을 향상시킬 필요가 있다.
이러한 분석 결과는 학문적·정책적으로 다음과 같은 시사점을 제공한다. 항공 수요 예측에서 정형 데이터의 한계를 보완하기 위해 비정형 데이터를 계량경제학적 모형에 결합하는 새로운 분석 프레임워크를 제안하고, 그 적용 가능성을 탐색적으로 확인하였다는 데 의의가 있다. 비록 소표본의 한계로 인해 통계적 유의성은 확보하지 못하였으나, 전통적 변수만으로는 설명하기 어려운 수요 변동을 설명하기 위한 시도로서 전통적 정형 변수만으로 설명이 어려운 단기 수요 변동을 온라인 기반 관심도 지표가 보완할 수 있음을 확인하였다. 항공사와 공항 운영기관은 외부 충격 발생 시 공급·가격 조정을 위한 신속한 의사결정에 온라인 수요 지표를 활용할 수 있으며, 정책 당국은 이를 조기경보 체계 구축에 응용할 수 있다. 본 연구의 분석 틀은 한국-베트남 노선뿐 아니라 다른 국제노선, 나아가 철도·버스·해운 등 다른 교통수단의 수요 분석에도 확장 적용이 가능하다.
종합적으로, 본 연구는 소표본·약한 도구라는 실증적 제약 속에서도 정형·비정형 데이터의 결합과 연립방정식 추정을 통해 항공 수요·가격 구조를 다면적으로 해석할 수 있음을 입증하였다. 이는 변화하는 국제여객 시장에서 실시간 데이터 기반 의사결정의 필요성을 부각시키는 동시에, 향후 데이터 융합형 계량경제학 분석의 토대를 제공한다.
