

Ⅰ. 서론
Ⅱ. 사용자 요구사항 분석
1. 전문가의 기존 포장 평가 방식
2. 목표 프로그램의 개요
3. 유저 여정 지도 작성
4. 분석 다이어그램 구상
Ⅲ. 사용자 요구사항 솔루션(딥러닝 모델 선정)
1. 딥러닝 모델 개요
2. 이미지 분류(Image Classification)
3. 객체 탐지(Object Detection)
4. 강건한 도로 데이터 학습을 위한 전처리 전략
Ⅳ. 사용자 요구사항 실현(프로그램 설계)
1. 모델 학습 및 추론 구조
2. 프로그램 아키텍처 설계
3. 프로그램 아키텍처 구현(코드화)
Ⅴ. 결론(기여 및 향후 과제)
Ⅰ. 서론
미국토목학회(American Society of Civil Engineers, ASCE)의 2025년 보고서[1]를 포함한 각종 조사[2,3]에 따르면, 도로 및 공항 포장 관련 비용이 꾸준히 상승한다고 보고했다. 도로면을 포장하려면 내구성 및 평탄성을 안전하게 유지하는 것이 항상 중요하며, 도로포장을 위해선 국제적인 표준에 기반한 정량적인 평가가 사전에 이뤄져야 한다.
PCI (Pavement Condition Index, 포장상태지수) 평가는 ASTM D6433[4]에 의해 표준화된 척도이며, 미군을 비롯한 각국에서 재포장 기준으로 널리 사용 중에 있다. PCI 평가는 포장의 구조적 건전성과 표면의 운영 상태를 나타내기에, 보수의 필요성을 제공하고 예산 계획과 의사 결정에 중요한 역할을 해준다. 그렇기에 실제 국내 공항 현장(인천국제공항, 한국공항공사 등 다수 기관)에서도 정기적으로 포장 상태를 평가하고, 콘크리트 및 아스팔트 보수의 우선순위를 결정하고자 PCI 평가를 적극 활용하고 있다[5]. 해당 방식은 포장면을 특정 기준 및 편의에 기반하여 나누는 것으로 시작한다. 브랜치와 섹션, 샘플, 슬래브 단위로 점차 세분되며, 한 아스팔트의 샘플 단위는 보통 20 ± 8개의 슬래브로 정의된다. 이후 상태 조사가 진행되며, 전문가는 시각적 조사(visual survey)에 기반하여 슬래브 내 포장의 파손 유형(distress type), 심각도(severity), 양(quantity)을 식별하여 기록한다. 각 샘플 단위에 대한 개별 데이터가 구성되면, 이후 공제 값을 결정하여 최종적인 점수를 0 (파손)부터 100 (완벽) 내의 수치 범위로 계산[6,7]한다.
그러나 해당 방식은 포장면의 조사가 반드시 수작업으로 이뤄져야 하는 단점이 있다. Micro PAVER와 같은 프로그램을 통해 계산의 수고를 줄일 수 있으나, 이는 반복된 작업 시간을 줄여주지는 못한다. 따라서 조사 범위가 넓은 활주로나 장거리 고속도로의 경우, 시간 소요가 기하급수적으로 증가하는 것이 실정이다. 그렇기에 실제로 전체 도로 구간의 10% 정도만 표본으로 삼아 PCI를 산정하는 것이 일반적이다. 하지만 이는 상태가 매우 나쁜 샘플이 조사에 포함되지 않거나, 우연히 발생한 결함이 부적절하게 표본에 포함되는 ‘샘플링의 한계’를 초래한다. 아울러 점수 평가에 참여하는 조사원이 여러 명일 경우 객관성 또한 저하될 수 있다. 특히 슬래브 내 포장의 심각도를 보는 기준이 상이할 수 있다. 이는 점수 산정의 일관성과 신뢰도에 큰 영향을 줄 수 있는데, 예를 들어 전문가들은 콘크리트의 선 균열이나 단면 보수 결함의 심각도 산출에 불일치된 의견을 내놓곤 한다. 각 결함별 공제 값은 심각도에 크게 의존하는데, 이는 PCI 산출에 큰 영향을 끼치게 된다. 한편, 작업자의 반복된 작업은 주관의 변형이나 오류를 초래할 수 있고, 평가자의 피로도가 점수 산출의 당위를 낮추는 상황이 발생할 수 있다.
따라서 근래에 딥러닝이 여러 태스크에서 높은 성능을 가져다줬기에, 이러한 결함 식별 과정을 컴퓨터 비전 모델로 활용하려는 연구가 많았다[8]. 주로 지도학습(supervised learning)이 사용됐으며, 라벨링된 도로 이미지 데이터셋(RDD2022[9], SVRDD[10], GAPs[11] 등)을 바탕으로 다양한 포장 결함을 탐지하는, 분할 및 탐지 모델이 많이 제안돼 왔다. 대표적으로 합성곱 신경망(Convolutional Neural Network, CNN) 기반의 YOLO[12]나 U-Net[13] 아키텍처가 사용됐으며, 최근에는 자연어처리에서 비약적인 성능을 거둔 트랜스포머 계열의 모델[14] 또한 제안되기도 했다. 하지만 기 제안된 모델들이 여러 지표(mAP50, etc.)에서 높은 정확도를 달성했다고 보고했으나[15], 이는 일부 데이터셋에만 국한되는 경우가 다수였다[16]. 예컨대 현실의 도로 환경은 영향받는 요인(촬영 조건, 날씨 등)이 매우 다양한데, 이는 AI의 강건함을 저하하는 주요 요인이 되어 자동화된 PCI 산출을 위한 모델 설계를 쉽게 지연시킨다. 게다가, 도로포장 분야는 소프트웨어 설계와 관련해 공유된 실제 사례가 많이 부족하기에, PCI 산출까지의 전체 과정을 자동화하려는 소요가 있음에도 상용 소프트웨어 개발은 초기 단계에 정체되고 있다[17].
이러한 이유로 본 논문은 ‘AI 기반 PCI 평가 소프트웨어 설계’의 기초 사례를 공유하여, 관련 상용 프로그램 개발이 활성화 되기를 독려한다. 대한민국 공군 공병대대 측의 실제 요구사항을 기반으로, 프로그램 설계에 필요한 컴포넌트와 클래스를 형상화한다. 이후 프로그램 설계를 위한 단계별 구상도를 UML (Unified Modeling Language, 통합 모델링 언어)과 함께 제시한다. 이때 PCI 평가 과정의 자동화를 위해, 선정한 딥러닝 모델의 학습 전략(초고해상도 데이터 정제, 데이터 증강, 모델 학습 전략) 또한 함께 서술한다.
본 논문은 사용자의 ‘요구사항 분석 - 요구사항 솔루션(딥러닝 모델 선정) - 요구사항 실현(프로그램 설계) - 결론(기여 및 향후 과제)’의 흐름으로 전개한다. II장에서 프로그램 설계를 위한 요구사항의 수렴 과정과, 사용자 입장에서의 소프트웨어 예상 흐름을 UML로 소개한다. III장에서는 PCI 평가 과정의 자동화를 위해, 컴퓨터 비전 중심의 딥러닝 연구를 검토한다. 이후, 공군 자체 데이터셋에 대해 정량적 지표를 비교 평가하여 YOLOv11이 선정된 이유를 함께 서술한다. 한편, 도로 균열은 배경과 유사하여 모델의 성능이 쉽게 저하되는 문제(단순 적용 정확도: 78.7%)가 있다. 따라서 우리는 강건한 학습을 위해 활용한 데이터 증강 기법에 대해서도 정량적인 평가와 함께 서술(최종 정확도: 86.8%)한다. IV장에서는 II장과 III장의 방법을 결합하여, 설계된 프로그램의 전체 구조를 설명한다. 이때, 데이터의 흐름을 도식화하고 요구사항의 실제 구현(의사 코드)을 공유한다. 마지막으로 V장에서는 전반적인 요약을 속도 측면의 기여(작업 시간 효율 98.2% 개선)와 함께 서술하고, 향후 과제 등을 언급한다.
Ⅱ. 사용자 요구사항 분석
이 장에선 프로그램 설계의 초기 단계인 요구사항 분석에 대해 서술한다. 사용자의 요구사항을 구체화하는 것은 체계적인 프로그램 구상에 가장 중요하다. 먼저 기존 전문가의 평가방식을 살피어 소프트웨어가 제공할 기능 집합을 파악하고, 자연어로 명세화(Software Requirements System, SRS)한다. 이를 바탕으로 사용자의 경험 흐름과 분석 다이어그램을 그리어 사용자 입장에서의 프로그램 흐름을 그려낸다.
본 소프트웨어는 대한민국 공군 공병대대의 실제 작전 및 유지보수 소요를 기반으로 착수됐으며, 소속 장병과의 면담을 통해 요구사항을 전달 받았다. 구체적으로, 1개 기지 비행포장면 평가를 위해서 장병 3명이 3주간 결함 표시 및 후처리를 진행해야 한다고 밝혔다. 따라서 사용자는 해당 과정이 몇 시간 내로 최적화되기를 희망했고, 이를 위해선 전문가의 기존 포장 평가 방식이 자동화 돼야 함을 알렸다. 이때, 사용자는 프로그램 내에서 이미지를 대규모로 업로드할 수 있어야 하며, AI 기반으로 이미지 분석이 가능해야 함을 알렸다. 이후 분석된 자료는 태그를 기반으로 추적할 수 있어야 하며, 분석 결과를 상세히(사진 별로) 조회할 수 있어야 한다고 말했다. 특히, 분석 결과 조회 시 탐지된 결함을 자유롭게 수정하거나 삭제할 수 있어야 하며, PCI 점수는 계속해서 동적으로 자동 계산돼야 한다고 말했다. 해당 소요는 향후 프로그램 설계의 기본 자료로 활용하고자, 하나의 문서로 정리해 명세화했다.
1. 전문가의 기존 포장 평가 방식
PCI 평가는 포장 관리 프로그램(PMS)의 핵심 기능으로, 포장의 현재 상태를 백분위로 환산한 점수 지표다. 총 4단계에 걸쳐 계산되며, 각 단계별 상세 내용은 아래와 같다.
1) 공제 값 결정(detect value) : 각 파손별 유형 및 심각도의 총량을 합산하고, 이를 샘플 단위의 총 면적으로 나누어 밀도(%)를 구한다. 이때 파손 공제 값 곡선(distress deduct value curves)을 통해 각 파손 조합에 대한 공제 값을 결정 시켜준다.
2) 최대 허용 공제 횟수(m) 결정 : 가장 높은 개별 공제 값(highest deduct value, HDV)을 사용하여 최대 허용 공제 횟수를 결정한다.
3) CDV (최대 보정 공제 값) 결정 : 모든 개별 공제 값의 총합(total deduct value, TDV)과 m 값을 사용하여, 보정 공제 값 곡선(correction curves)에서 최대 보정 공제 값을 반복적으로 결정한다.
4) PCI 계산 : 100에서 최대 보정 공제 값(corrected deduct value, CDV)을 빼어 PCI를 산출한다. 섹션의 PCI는 샘플 단위의 PCI를 평균내어 결정하며, 샘플 단위 크기가 다를 경우 면적 가중 평균이 사용된다.
2. 목표 프로그램의 개요
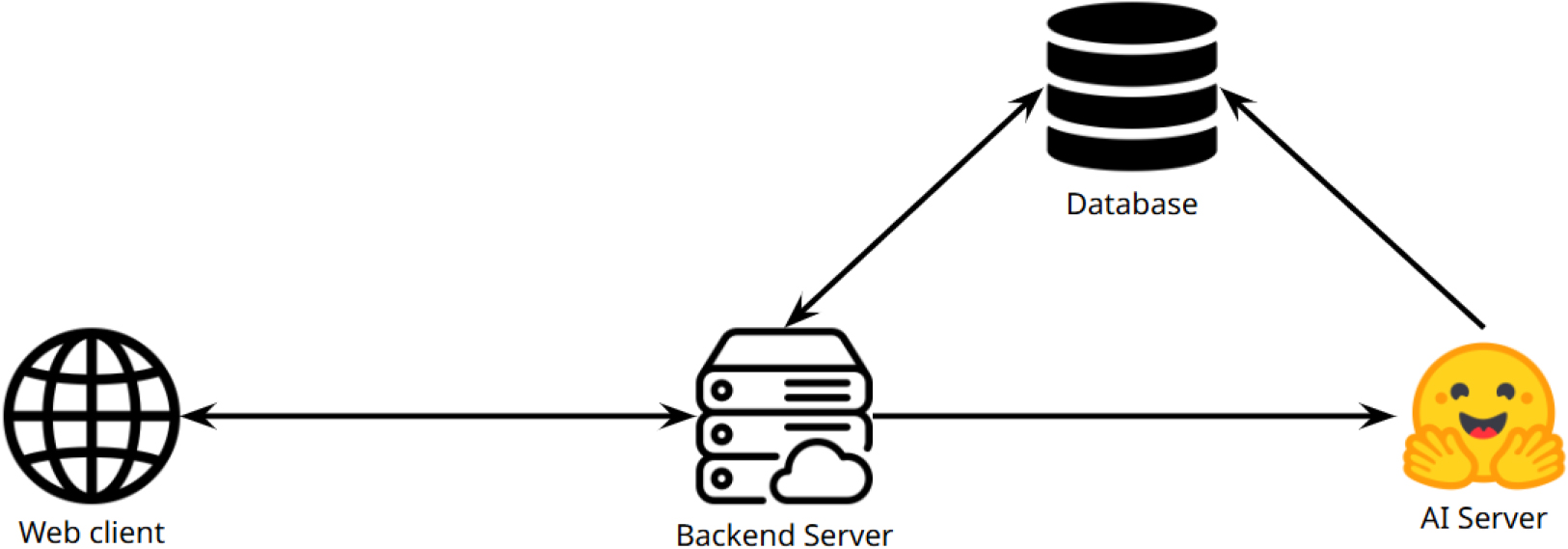
IEEE 830에서 제정한 규격을 참고[18]하여, II.1 및 공병대대의 요구사항으로부터 프로그램의 포괄적인 기능 집합이 제공돼야 한다. 우리는 요구사항에 기반하여 프로그램을 (1)기능성과 (2)배포환경으로 나누어 설계의 기초를 간단히 다졌다. 이때, 프로그램 기획자는 중요하게 구현돼야 할 기능들을 (때로는 ID를 부여하여) 유닛별로 작성한다. 이후 필요한 최소 하드웨어 자원을 파악하여 클라이언트와 서버 간의 간단한 관계도를 그려낸다.
우리의 자동화된 PCI 평가 프로그램에선, 분석을 위해 대규모 이미지를 업로드할 수 있어야 한다. 그리고 AI를 도입해 PCI 점수를 자동으로 산출해야 한다. 또한 과거의 이력을 조회하기 위해 데이터베이스(DB)에 정보를 보관하거나, 태그를 기반으로 이력을 추적할 수도 있게 해줘야 한다. 이러한 사항을 기반하여, 프로그램 설계를 위한 기능성과 배포 환경을 간단하게 나타내면 Fig. 1과 같다.
1) 기능성(Functionality)
기능성은 사용자가 본 프로그램을 통해 ‘무엇을 할 수 있는지’에 초점을 맞춘다. 이를 위해 담당자는 어떤 기능들이 프로그램에서 제공돼야 하는지를 가볍게 정리한다. Table 1은 제공할 프로그램의 기능 요구사항 예시다.
Table 1.
Sample Functionality of Our System
2) 배포환경(Deployment)
담당자는 위에 작성된 기능을 토대로, 프로그램이 ‘어디서 어떻게 실행돼야 하는지’를 배정한다. 각 기능들의 실행 노드와 역할은 어떤지, 흐름이 포함된 다이어그램을 그리어 Fig. 1과 같이 프로그램의 구성을 표현한다. 이때, 각 사용자(고객, 관리자 등)들은 어떤 노드를 사용하는지 명시돼야 한다.
3. 유저 여정 지도 작성
한편, 기능 요구사항을 정리할 때에는 사용자의 페르소나도 같이 정의하는 것이 일반적[19]이다. 페르소나는 프로그램을 이용할 가상의 사용자를 말하며, 보통 해당 사용자의 직업, 선호도, 행동 등을 작성한다. 본 논문에서는 ‘공병대대 측 장병’으로 페르소나를 선정했다. 이후 담당자는 사용자 경험(User eXperience, UX)의 흐름을 정의하고, Table 1에서의 기능 요구사항을 기반으로 상세 시나리오를 작성한다. 시나리오에는 각 프로그램(Front-end, Back-end, AI)의 상호 흐름 관계가 나타나야 하며, 본 논문의 사례에서는 다음과 같이 예시를 들 수 있다(이때 숫자는 요구사항 ID다):
... 유저는 웹에서 001 후 002를 요청하고, 003 및 004, 005를 할 수 있다. 이때, Back-end에서는 006을 하여 결과 값을 Front-end에게 지속적으로 제공해야 한다. AI는 004를 수행한 결과를 데이터베이스에 저장하여 향후 Back-end에게 정보를 건네준다. ...
시나리오 작성이 완료되면 유저의 여정 지도를 작성할 수 있으며, 자동화된 PCI 평가 프로그램을 위한 유저 여정 지도를 간단히 그리면 Table 2와 같다.
Table 2.
User Journey Map Through System Scenario
4. 분석 다이어그램 구상
IV장에서 언급될 요구사항 설계를 위해, 먼저 SRS (명세)를 UML[20]을 통해 각자의 역할이 도식화돼야 한다. 그 이유는 SRS가 자연어로 작성됐기 때문에 사용자, 기획자, 개발자, 디자이너가 서로 해석의 차이를 가질 수 있기 때문이다. 유형에 따른 다양한 다이어그램이 존재하지만, 여기에서는 유즈케이스(usecase) 다이어그램과 활동(activity) 다이어그램만을 나타낸다. 참고로 본 논문에서 작성되는 모든 UML은 ISO/IEC가 승인한 OMG (Object Management Group)의 공식 규격 문서[13]에 기반한다.
1) 유즈케이스 다이어그램
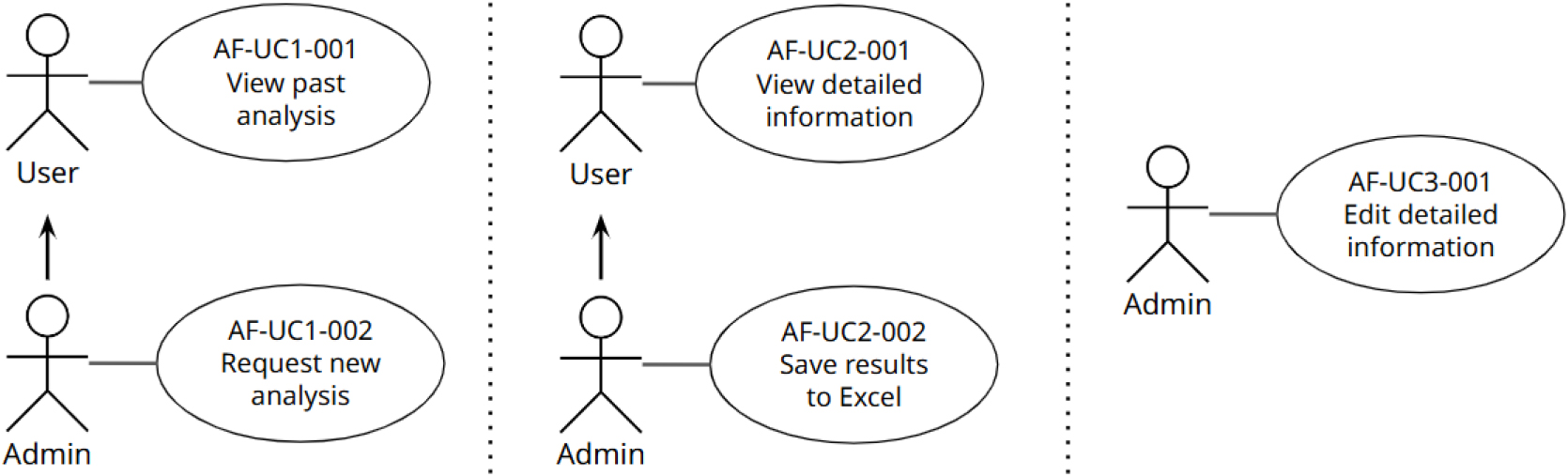
유즈케이스 다이어그램은 객체 및 소프트웨어 기능을 위한 함수 생성에 큰 도움을 준다. 유즈케이스 다이어그램을 작성할 때에는 프로그램의 경계가 명확히 드러나야 한다. 본 다이어그램은 프로그램이 외부 사용자(액터)에 의해 어떤 기능을 제공하는지 표현하는 모델이다. 즉, 사용자 중심의 정의를 그리며, 프로그램, 기능 단위로 나눈 행위(유즈케이스)와 액터 간의 관계를 화살표를 활용하여 나타낸다. 이때 프로그램 구조보다도 액터가 프로그램을 통해 어떤 활동을 할 수 있는지 잘 그룹화 해야한다.
자동화된 PCI 평가 프로그램에선 사용자에게 분석 정보를 제공하거나, 권한에 따라 신규 분석 요청을 받을 수 있다. 상세 정보를 제공하고 수정 권한을 부여할 수 있으며, 결과를 엑셀로 제공할 수 있다. 프로그램의 유즈케이스는 Fig. 2와 같다.
2) 활동 다이어그램
활동 다이어그램은 하나의 유즈케이스가 실행될 때의 프로세스를 시간 순서대로 표현한다. 이는 프로그램의 작업 수행 순서 및 내용을 중심으로 시각화하여, 절차의 부가 설명 및 UI (User Interface, 유저 인터페이스)와의 연동에 도움을 준다. 보통은 시작 지점과 종료 지점에 대한 내부 흐름을 실행 단계, 분기, 병렬 여부, 화살표를 통해 나타낸다. Figs. 3과 4는 위에서 작성한 유즈케이스를 기반으로 그린 활동 다이어그램의 예제다.
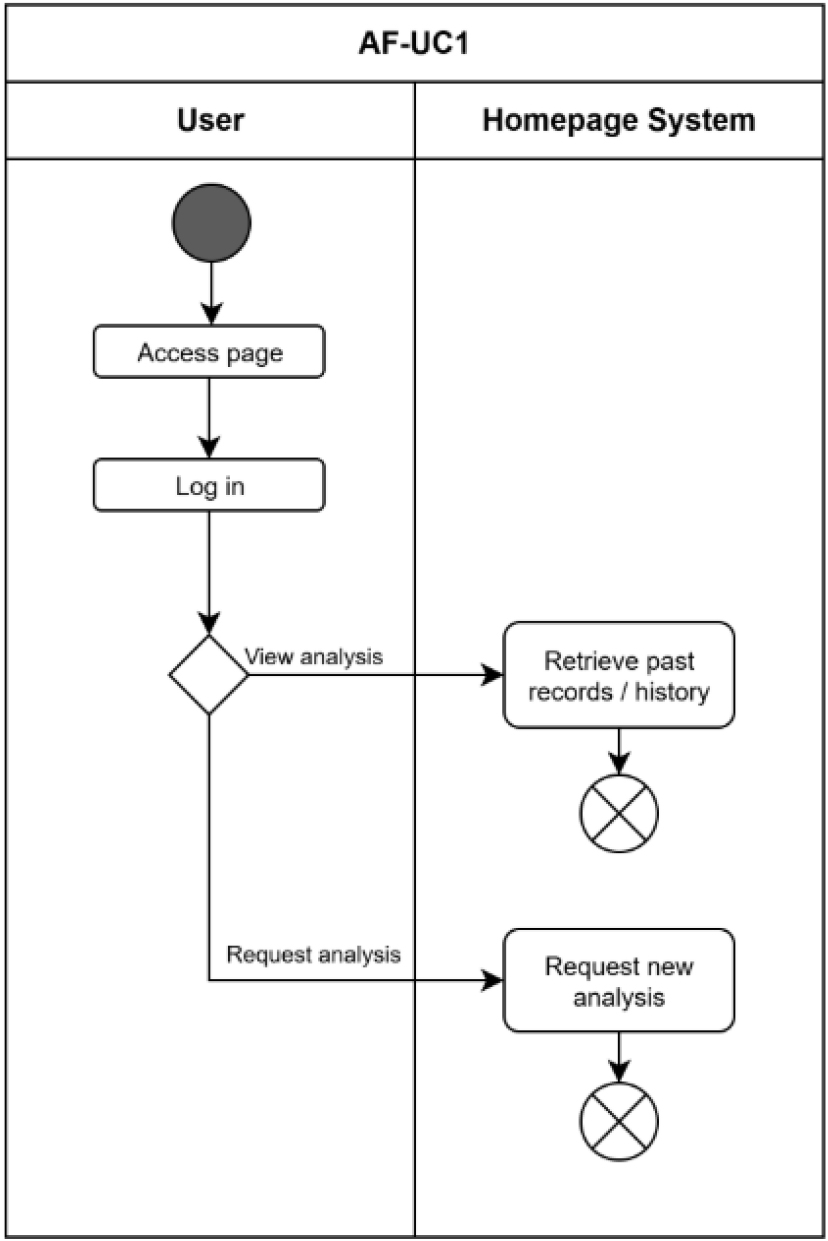
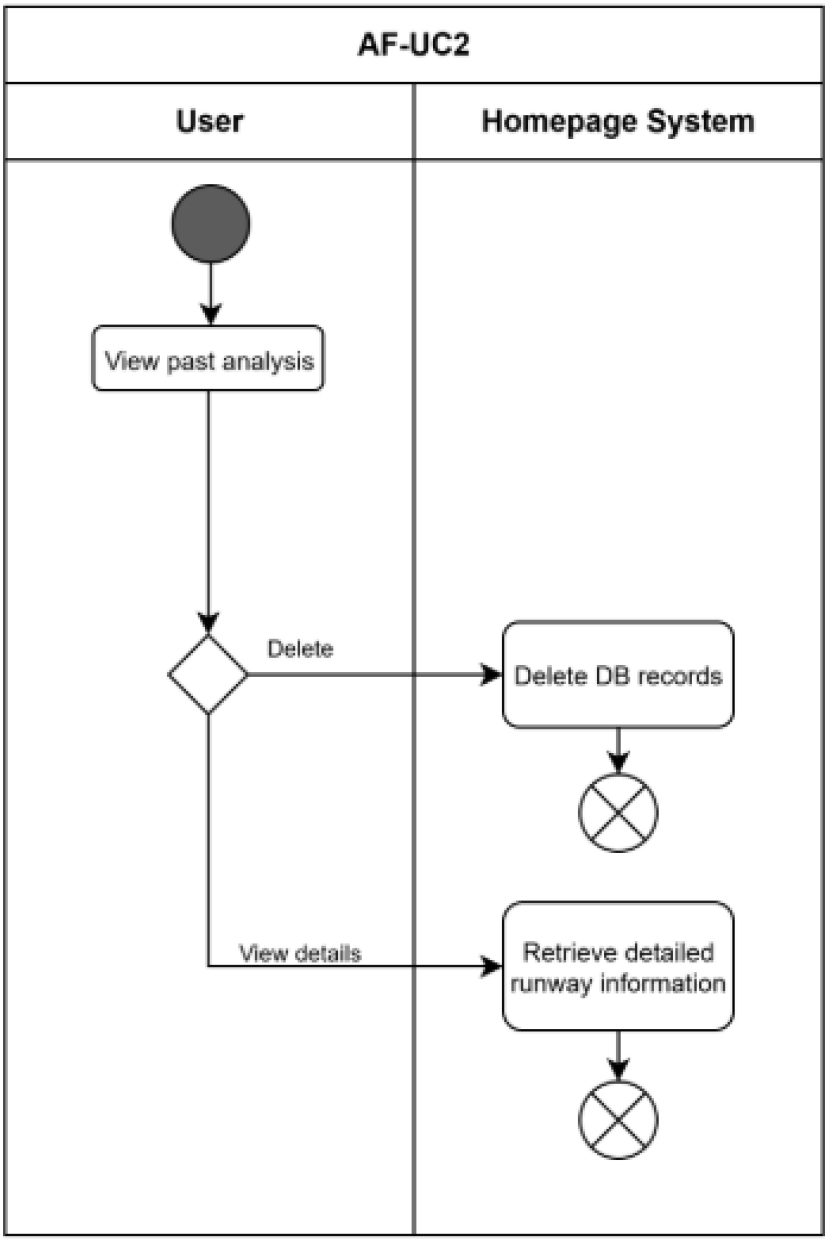
Ⅲ. 사용자 요구사항 솔루션(딥러닝 모델 선정)
이 장에서는 도로 균열을 자동으로 탐지하기 위한 딥러닝 모델에 대해 서술한다. 컴퓨터 비전 분야에서 딥러닝이 대두된 배경을 시작으로, 프로그램에 적합한 모델 선정 및 추론 구조까지의 전반적인 내용을 다룬다.
1. 딥러닝 모델 개요
컴퓨터 비전은 기계가 이미지를 인간의 시각처럼 이해하고 처리하게 하는 학문 분야로, 기본적인 작업은 이미지 분류(image classification), 이미지 분할(image segmentation), 객체 탐지(object detection) 등으로 나뉜다. 그 구현 방식 중 딥러닝은 빅데이터를 기반으로 패턴을 학습하는 인공신경망의 발전 형태인데, 2012년 이미지넷(ImageNet)[21] 대규모 시각 인식 챌린지(ILSVRC)에서 알렉스넷(AlexNet)[22]이 압도적인 성능(Top-5 오류율 약 15%, 기존 대비 10% 향상)을 달성하며 그 효과를 주목 받기 시작했다. 본 프로그램은 도로 포장 상태 평가에 필요한 균열 유형을 자동으로 식별하고자, 딥러닝 기반의 이미지 분류와 객체 탐지를 핵심 기술로 선정한다. 탐지된 균열의 개수, 유형, 크기 등 구체적인 도로 내 시각적 정보가 PCI 점수 평가에 직접적으로 반영되기 때문이다. 객체 탐지 모델은 이미지 내에서 특정 객체의 위치(bounding box)와 범주를 동시에 예측하기에, 탐지된 균열을 좌표로 환산 가능하며, 시각화 및 정량적 분석에 용이하다는 장점이 있다. 이미지 분류 모델은 객체 탐지 모델이 학습하기엔 탐지 영역이 큰 결함(e.g., map cracking)을 위해 부가적으로 사용한다.
2. 이미지 분류(Image Classification)
컴퓨터 비전의 이미지 분류 모델은 주로 LeCun 등[23]이 우편번호 탐지를 위해 활용하기 시작한 합성곱 신경망(CNN)에 기반한다. 이는 2차원 정보에 점수를 부여함과 동시에 수용 영역(receptive field), 공유 가중치(shared weight), 서브 샘플링(pooling)을 가능하게 하여 연산자가 왜곡에 대해 불변성을 지니도록 한다. 그러나 최근 트랜스포머(transformers)[24]가 가져다준 자연어처리의 비약적인 성능 개선으로, 컴퓨터 비전 분야에서도 트랜스포머를 사용하려는 움직임이 강해졌다.
현재 SOTA (state-of-the-art)를 등극한 모델의 대다수가 트랜스포머 구조(Vision Transformer, ViT)[25]를 활용하고 있는데, 이는 트랜스포머 계열의 모델이 귀납적 편향(inductive bias)이 약해 모델의 표현력(capacity) 한계를 극복했기 때문이다. 특히, 어텐션(attention) 연산자는 토큰 정보를 전역적으로 학습하기에, ViT는 이미지 전체적인 특징을 고려하기에 훨씬 유리하다. 비록 모델의 파라미터가 크고 학습 시 소요 시간이 길지만, 슬래브에 전체적으로 나타나는 균열을 높은 정확도로 분류하고자 우리는 트랜스포머 계열의 모델을 이미지 분류 작업에서 사용한다.
3. 객체 탐지(Object Detection)
객체 탐지 모델은 정확도를 중시하는 Two-Stage 모델(R-CNN)[26,27,28]과 속도를 중시하는 One-Stage 모델(YOLO)[10]로 나눌 수 있다. Two-Stage 모델은 객체의 후보 위치를 먼저 추출한 뒤, 각 영역을 분류하는 방식을 택한다. 이는 정확도가 높지만 연산량이 많아 속도가 느리다는 단점이 있다. 반면, One-Stage 모델은 한 번의 연산으로 객체의 위치와 범주를 동시에 예측하여 비교적 빠른 속도를 지닌다.
물론 DETR[11,29]과 같은 트랜스포머 계열의 모델 또한, 전체 이미지 컨텍스트를 고려하기에, 복잡한 객체의 관계를 잘 학습하는 장점이 있다. 그러나 모델의 크기와 복잡성으로 인해 학습 속도가 느리고, 많은 연산 자원을 요구하는 경향이 있다. 프로그램을 위한 군 내 자체적인 활주로 데이터셋을 학습해본 결과, YOLO 계열이 R-CNN, DETR에 비해 mAP50 (mean Average Precision) 수치가 근소하게 높았으며, 실시간 처리 및 프로그램의 환경 효율성을 고려하여 YOLO를 우리의 핵심 모델로 선정하게 됐다. 구체적인 성능 비교표는 Table 3과 같으며, YOLO 모델 중에서 우리는 가장 효율적인 학습 시간과 성능을 보여준 YOLOv11[30]의 기본(Medium)을 프로그램에 활용했다. Table 3에서, ms는 모델이 하나의 이미지를 처리하는데 걸리는 밀리초를 의미한다. mAP (mean Average Precision, 평균 정밀도)는 모델이 예측한 객체의 위치가 실제 정답과 얼마나 일치하는지 정밀도(Precision)과 재현율(Recall)을 종합적으로 고려하여 계산하는 정량적인 결과다. 이때, IoU (Intersection over Union, 모델이 예측한 객체 위치와 실제 객체 위치의 겹치는 정도)에 따라 50 또는 95 등의 숫자가 붙으며, 본 문헌에서는 mAP50 (50%)를 활용한다.
Table 3.
Comparing Model Performance via mAP50 Metrics
| Category | R-CNN (ResNet-50) | DETR (ViT-B) | YOLOv11 (Medium) |
| Performance (mAP50) | 71.4% | 76.3% | 78.7% |
| Inference Time (ms) | 200 | 56 | 7 |
참고로, YOLOv11에서 사용된 핵심 연산자를 간단히 설명하면 아래와 같다.
1) SPPF
SPP (Spatial Pyramid Pooling)[21] 블록은 2015년에 제안된 개념으로, 이미지 크기와 관계 없이 고정된 크기의 특징 맵을 추출하여 결합한다. 이는 합성곱 신경망(CNN)이 다양한 규모의 객체를 인식하도록 도우며, YOLOv4[32]부터 다크넷(Darknet)과 함께 백본에서 사용됐다. YOLOv5[33]에서는 SPP 블록을 최적화한 SPPF (Spatial Pyramid Pooling - Fast)가 도입됐는데, 이는 SPP와 동일한 출력을 제공하면서도 병렬 풀링 연산을 순차적으로 수행하여 더 빠른 처리속도를 지니게 한다.
2) C2PSA
C2PSA는 YOLOv11에서 새로 제안된 블록으로, 이전 YOLO와 달리 공간 어텐션(spatial attention)을 도입한다. 어텐션은 모델이 입력 데이터에서 중요한 특징에 집중할 수 있도록 돕는 방식으로, 트랜스포머와 같은 연산자에서 주요하게 사용된 연산자다. 주로 이미지의 핵심 영역을 활성화하는 데 활용되며, C2PSA는 C2 (Cross Stage Partial with 2F connections)와 PSA (Pyramid Split Attention) 블록을 각각 결합한 구조다. 여기서 C2 블록은 CSP (Cross Stage Partial)의 변형으로, 이전 레이어의 일부를 다시 연산에 활용하는 CSP 블록의 개선된 버전이다. PSA는 채널 정보와 공간 정보를 전역적으로 고려하고자, 여러 크기의 특징 맵에 어텐션 연산을 진행하는 블록이다. 이로써 C2PSA는 작거나 부분적으로 가려진 객체에 대해도 탐지 정확도를 높일 수 있어 YOLOv11에 차별점을 가져다 줬다.
3) C3K2
C3K2 블록 또한 CSP 계열로, C2 대신 C3 블록에 Bottleneck (병목) 블록 2개를 결합한 방식이다. Bottleneck이 작을수록 속도가 빨라지는 이점이 있는데, 기존의 YOLOv7[34]에서는 스테이지 별로 블록을 여러 개로 나눈 반면, YOLOv11에서는 2개만 활용하여 보다 빠른 처리 속도를 지닌다.
4. 강건한 도로 데이터 학습을 위한 전처리 전략
딥러닝 모델이 도로 내 균열을 일관되게 탐지하기 위해, 아래와 같은 전처리 전략을 추가로 활용한다.
1) 그레이스케일 정규화
도로 이미지는 촬영 환경(날씨, 조명)에 따라 밝기, 명도, 색상 등이 크게 달라져 모델의 학습을 방해한다. 따라서 해당 문제를 해결하고자 우리는 학습 데이터셋에 그레이스케일 정규화를 적용한다. 이는 컬러 정보를 제거하고 밝기 정보만으로 이미지를 통일시켜, 모델이 환경 변화에 덜 민감해지고 도로의 핵심 특징에 집중하도록 독려한다.
2) 데이터셋 내 범주 불균형 해소
도로 데이터는 범주 불균형(imbalance)이 심한 편이다. 예를 들어 선 균열은 단면 보수에 비해 빈도 수가 상당히 높은데, 이러한 불균형은 딥러닝 모델이 학습 과정에서 특정 범주에 편향된 가중치(weights)를 갖게 한다. 이는 상대적으로 수량이 적은 범주에 대한 식별 능력을 크게 저하시킨다. 우리는 학습의 안정성을 확보하고자 서브샘플링(subsampling) 기법을 적용한다. 각 결함별 샘플 수를 균등하게 조정하여 모델이 모든 범주의 특징을 동등하게 학습하도록 유도하는, 다시 말해, 특정 범주에 치우치지 않는 강건한(robust) 가중치 분포를 형성하도록 독려한다.
3) 다양한 데이터 증강 기법 활용
도로 데이터의 낮은 대비(배경과 결함이 유사함)는 모델이 학습될 때 혼동을 주기 쉽다. 따라서 우리는 모델의 성능을 높이고자 매우 다양한 데이터 증강(data augmentation)기법을 활용한다. 먼저, 학습 데이터 10,000장에 대해 기하학적인 변환(GT)을 추가하여 균열이 다양한 위치, 크기, 방향에 대해 학습되도록 한다. 실험을 통해 이미지의 회전 각도는 90도로 선정했고, 객체 좌표의 10% 범위 내에서 무작위 이동을 적용했다. 비율은 ±50%로 확대, 축소됐으며, 좌우 반전이 적용될 확률 또한 50%로 선정했다. 이후, 색상 및 픽셀을 HSV (Hue (색조), Saturation (채도), Value (명도))를 조정하여 모델이 색상 및 조도 변화에 둔감하도록 학습했다. 우리는 각각의 값을 수정하며 픽셀에 무작위 변환을 가했고, H = 0.015, S = 0.7, V = 0.4의 값을 본 모델에서 사용하기로 결정했다. HSV 조정은 기존 대비 1.7% 향상을 보여 성능 향상을 보였으며, 최종적으로 기하 변환이 적용된 모델은 그렇지 않은 모델 대비 2.43%의 성능 향상을 보였다.
한편, 혼합 증강 기법(MA)을 추가로 활용해 모델 학습에 견고함을 독려했다. 예를 들어 모자이크[32]는 여러 개의 이미지를 합쳐 새로운 학습 샘플을 만드는 기법이다. 이는 네 개의 이미지를 무작위로 선정하고 각각의 크기를 조절하여 하나의 큰 이미지에 새로이 붙인다. 해당 방식은 객체가 희소한 여러 이미지를 하나의 이미지로 결합하여 여러 장면에 대응력을 향상시킨다. 또한 두 개의 이미지를 잘라내고 붙여 새 샘플을 만드는 CutMix[35] 방식을 추가로 활용해, 부족한 학습 샘플의 수를 늘려 학습에 안정을 도모했다. 아래 Table 4는 데이터 증강을 통해 얻은 모델의 최종적인 성능 비교 결과표(여기서 기본은 YOLOv11-Medium만을 사용한 모델이다.
Ⅳ. 사용자 요구사항 실현(프로그램 설계)
이 장에서는 II장과 III장에서 다룬 내용을 기반으로, AI 기반의 PCI 프로그램 설계를 위한 전체적인 청사진을 공유한다. 먼저, 추가적인 이미지 정제 전략이 적용된 전체적인 딥러닝 파이프라인을 공유한다. 이후 프로그램의 실질적인 구현을 위해 핵심 컴포넌트(클래스)를 정의하고, 이들 간의 상호작용을 도식화하여 AI기반 도로 평가 소프트웨어에서 이뤄지는 데이터의 흐름을 표기한다.
1. 모델 학습 및 추론 구조
제안하는 프로그램의 전체적인 딥러닝 파이프라인은 Fig. 5와 같다. 입력 이미지는 추가 전처리 과정을 거쳐 도로의 특정 구간을 나타내는 ‘슬래브(slab)’ 단위(5750*5750 혹은 7620*7620) 픽셀로 분할된다. 이후 각 슬래브는 다시 N × N (이때 N은 임의의 자연수) 크기의 패치(patch)로 잘게 나누어 딥러닝 모델의 입력으로 사용한다. 이 패치들은 이미지 분류 모델(ViT)과 객체 탐지 모델(YOLO)에 각각 입력되어 학습 혹은 추론이 진행된다.
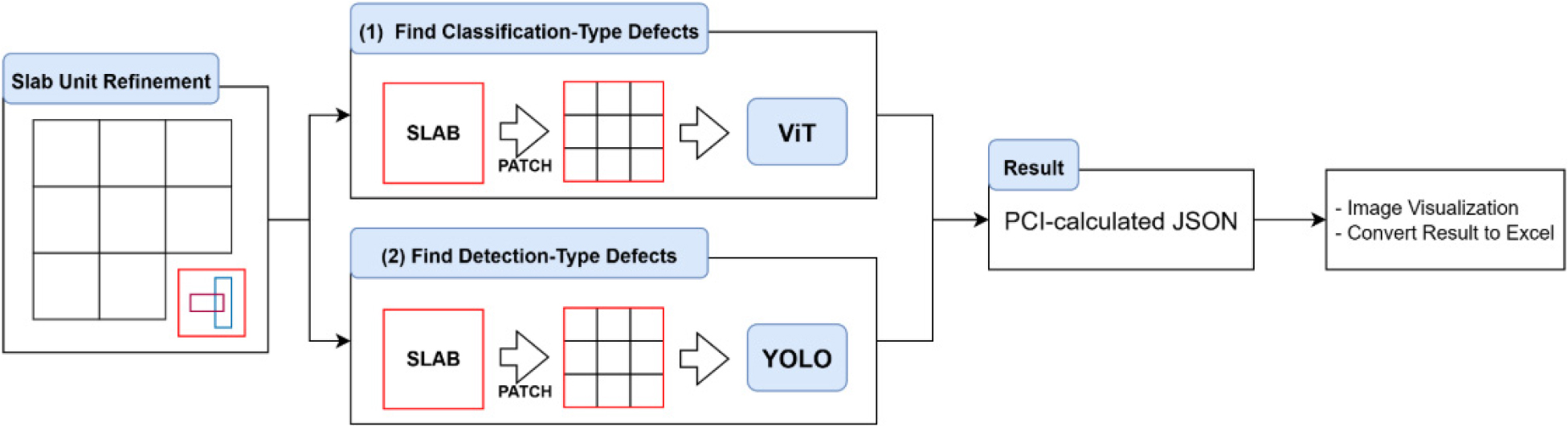
여기서 객체 탐지 모델은 각 패치 내에서 결함 객체를 탐지하고 해당 객체의 위치와 범주 정보를 추론한다. 이때 각 객체의 정보는 패치 기준이므로, 후처리 과정을 거쳐 각 패치에서 탐지된 객체 정보 및 정답 라벨을 하나의 슬래브 단위로 통합한다. 한 슬래브 내의 균열 정보가 정리되면, 각 결함별 유형을 계산식에 대입해 PCI 점수를 산정한다. 이후 탐지된 균열 정보와 최종 PCI 점수는 프로그램의 편의를 위해 사용자 정의 JSON 형식으로 직렬화한다. 이는 웹 서비스 영역(Back-end, Front-end)에서 이미지의 결함 정보를 가시화하거나, 사용자에게 결과 정보 엑셀을 제공하기 위해 사용된다.
2. 프로그램 아키텍처 설계
위 딥러닝 모듈이 포함된 실제 프로그램을 잘 구현하려면, 클래스를 적절히 선정하여 컴포넌트를 구성해야 한다. Front-end는 UI로 표기할 정보에 대해 Back-end에게 요청해야 하므로, 컴포넌트와 기능 사이에 실제로 어떤 데이터가 이동하는지를 시간 흐름대로 나타낼 수 있어야 한다. 다음에서는 이와 관련한 간단한 클래스, 시퀀스 다이어그램을 공유한다.
1) 클래스 다이어그램
기존에 ‘II. 사용자 요구 분석’에서 제안됐던 기능성을 기반으로 명사를 추출하여 구현해야 할 클래스를 식별한다. 적합한 클래스를 선별하기 위해선 선정된 후보들의 중복성, 무관성, 모호성, 소속(속성, 연산) 관계, 역할을 고려해야 하며, 각 클래스 간의 연결성을 살피어 관계를 모델링한다. 설계는 수준에 따라 예비(preliminary) 단계와 상세(detailed) 단계로 나눌 수 있는데, 전자의 과정에서는 각 클래스에 주요 속성 및 기본적인 연산을 부여하고, 후자에서는 이를 구체화한다. 자동화된 PCI 평가 프로그램의 예비 설계 수준 일부를 공유하면 Fig. 6과 같다. AI 기반 도로 포장 평가 프로그램을 위해, 사용자가 필요로 하는 컴포넌트는 요청(신호) 클래스로 간주할 수 있으며, ‘과거 분석 조회’, ‘신규 분석 요청’, ‘요청 리스트’, ‘딥러닝 분석 진행’, ‘분석 상세 정보’들이 그 예시다. 각 컴포넌트는 프로그램 내(특히, Back-end와 Front-end)에서 API (Application Programming Interface, 응용 프로그래밍 인터페이스) 형식으로 발생하는 데이터를 주고 받게 된다.
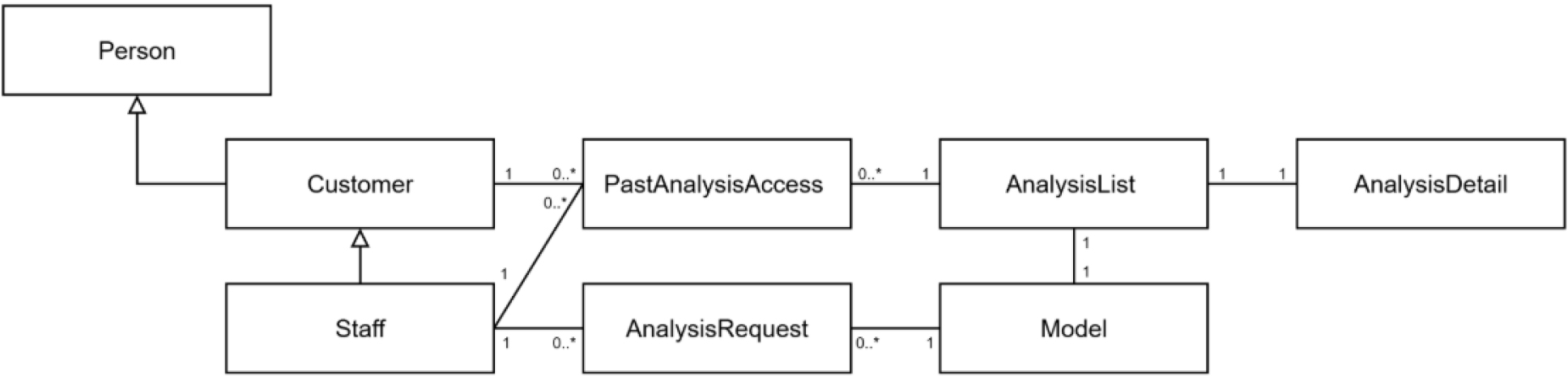
2) 시퀀스 다이어그램
시퀀스 다이어그램은 컴포넌트 간 상호 작용의 흐름을 보여주는 그림이다. 해당 상호작용은 컴포넌트 간의 교환되는 메시지의 순서로 정의되며, 유즈케이스의 시나리오를 최종적으로 구현하는 데에 사용된다. 액터와 컨트롤러 객체, 참여 객체가 서로 호출을 주거나 받으며 응답, 반환, 생성, 삭제와 같은 구체적인 작업을 그려낸다. Fig. 7은 본 프로그램에서 신규 평가를 요청하는 이벤트와 관련한 시퀀스 다이어그램을 나타낸다.
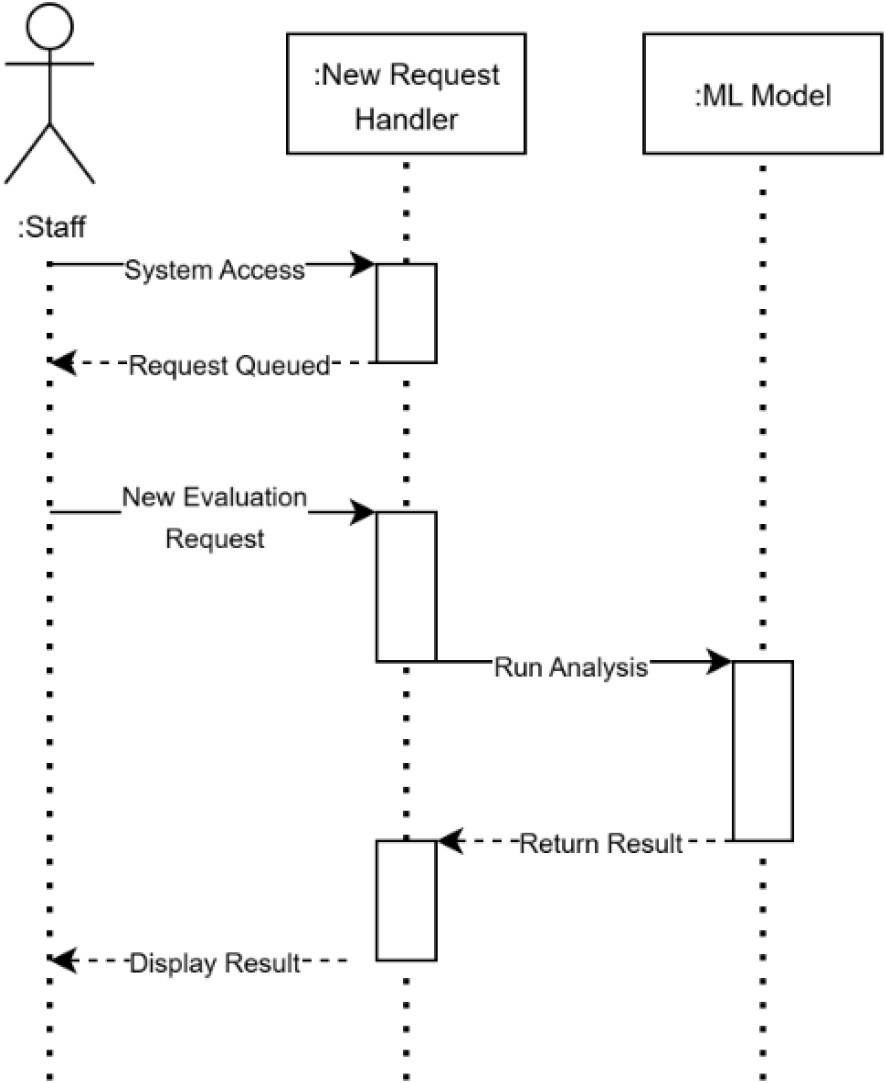
앞서 언급된 모든 설계 과정을 종합하여, 전체 프로그램의 흐름을 인프라 관계도로 나타내면 Fig. 8과 같다. AI 기반 PCI 평가 프로그램을 실제로 구현(코드화)하려면 사용자는 웹을 통해 네 가지의 컴포넌트(신규 분석 요청, 이미지 업로드, 정보 확인, 엑셀 저장)에 접근할 수 있으며, 해당 컴포넌트는 API를 통해 딥러닝 파이프라인과 DB로부터 데이터를 전달받는다.
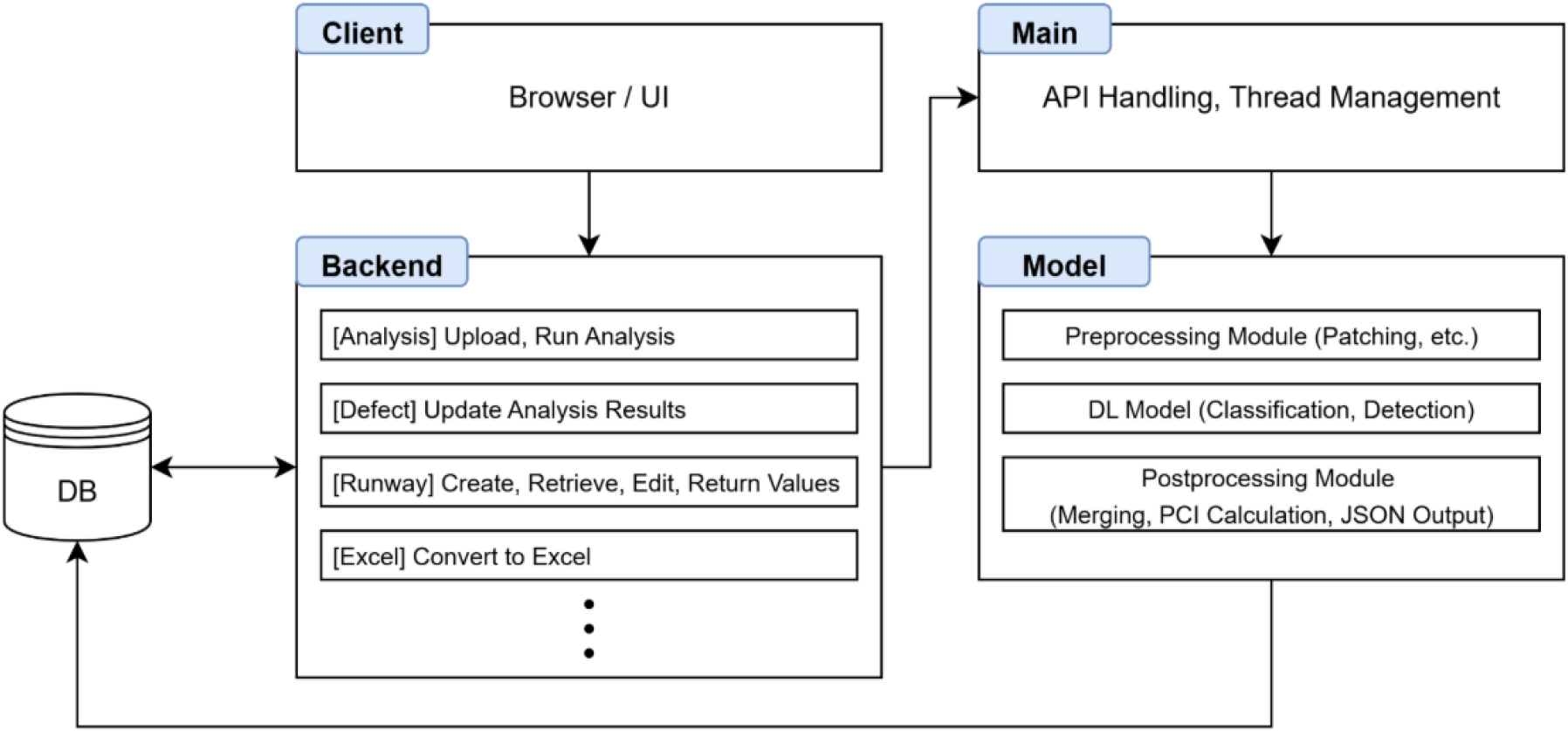
3. 프로그램 아키텍처 구현(코드화)
Fig. 8의 구조에서 사용자의 신규 요청으로부터 최종 결과를 얻기까지의 전체 과정(Main)을 의사 코드로 공유하면 Fig. 9의 Algorithms 1과 같다. 이때, PCI 계산을 위해 활용되는 후처리 모듈의 일부 구현을 Algorithms 2에 표기했다.

Ⅴ. 결론(기여 및 향후 과제)
본 논문은 실제 군용 비행 포장면의 유지보수 효율을 위해, AI 기반의 결함 탐지 소프트웨어 개발 사례를 제시했다. 군 내 실제 비교 테스트 과정에서, 1개 비행포장면에 대해 약 3주가 소요되던 평가 작업은, 제안된 소프트웨어를 통해 단 3시간 만에 완료됐다. 이는 전문 인력의 수고로움을 덜어 인프라 낭비를 방지하고, 도로 포장 관리의 효율성을 제공하는 획기적인 성과를 보인다(전문가의 하루 작업을 8시간으로 가정하면, 시간 절약률은 약 = 98.2%). 본 논문에서 우리는 공병대대 측의 실제 요구사항부터, 구현을 위한 기능성 도출, 솔루션 AI 모델 선정, 정량적 비교 평가 등, 구체적인 실현까지의 일련의 과정을 상세하게(다이어그램, 정량적 지표, 의사 코드 등) 나타냈다. 이는 보안 문제로 공유가 어려웠던 도로 관련 AI 서비스의 적절한 가이드가 되어, 유사 프로그램의 연구 및 개발이 촉진되는 데에 기여할 것이다.
물론 성공적인 결과에도 불구하고, 제안된 프로그램의 발전을 위해선 몇 가지 향후 과제가 존재한다. 먼저, 모델의 성능을 개선하여 보다 신뢰성 있는 결과를 제공하도록 노력해야 할 것이다. 또한 UX를 강화하여 사용자에게 높은 편의를 제공하는 프로그램이 되도록 노력해야 할 것이다. 이와 관련해 FURPS 모델[36]과 같은 체크리스트를 활용하여, 사용자가 결과(PCI 점수나 AI 모델)에 대해 얼마나 만족했는지 분석하는 것은 우리의 중요한 숙제가 될 것이다. 게다가 본 가이드를 기반으로 적용 범위를 확장하여, 민간 인프라(도로, 공항)에서도 사용이 가능하도록 다양한 솔루션을 추가로 모색할 필요가 있다.
