Ⅰ. 서론
1. 연구 배경 및 필요성
2. 관련 연구
3. 공군 활주로 크랙 데이터셋 개요
4. 데이터셋의 주요 기여 및 차별점
Ⅱ. 공군 활주로 크랙 데이터셋 상세
1. 데이터 전처리
2. 데이터셋 개요 및 구성
3. 메타데이터 구조 및 라벨링 형식
4. 원천 데이터 및 합성 데이터 구성
Ⅲ. 데이터셋 구축 과정
1. 데이터 구축 공정
2. 원시데이터 수집 및 확보
3. 데이터 전처리 및 정제
4. 합성 데이터 생성
5. 데이터 가공 및 라벨링
Ⅳ. AI 모델링 및 성능 평가
1. AI 모델링 방법론
2. AI 모델 성능 평가
Ⅴ. 실험 결과
1. 데이터셋 구성 및 학습 환경
2. 결함 분류 성능(mAP)
3. 합성 이미지 유사성(SSIM)
4. 시각적 튜링 테스트(VTT)
5. 모델 성능 유사도
6. 합성 이미지 품질 평가(FID)
7. 모델 시뮬레이션 결과
Ⅵ. 결론 및 향후 연구
1. 결론
2. 향후 연구
Ⅰ. 서론
1. 연구 배경 및 필요성
활주로는 항공 작전의 핵심 기반 시설로서, 그 표면 상태는 항공기의 안전한 이착륙에 결정적인 영향을 미쳤다. 균열, 소파, 스폴링 등 다양한 형태의 결함은 항공기 타이어 손상, 이물질 흡입(Foreign Object Debris, FOD) 발생, 활주로 표면 마찰 계수 저하 등을 유발하여 항공 작전의 안전성과 효율성을 저해할 수 있었다. 따라서 활주로 표면의 정기적이고 정확한 결함 검출 및 유지보수는 항공 작전의 연속성과 안전성 확보에 필수적인 요소로 간주되었다[1].
기존의 활주로 결함 검사는 주로 숙련된 작업자의 시각적 조사에 의존하였다. 이러한 방식은 광범위한 활주로 면적을 검사하는 데 막대한 시간과 인력을 소모하였으며[2], 작업자의 피로도나 주관적인 판단에 따라 검출 정확도 및 일관성 확보에 문제를 초래하였다[3]. 특히, 야간이나 악천후와 같은 불리한 환경 조건에서는 검사 수행 자체가 어려운 경우가 많았으며, 유지보수 주기를 준수하기 어렵게 만들었다.
최근 딥러닝 기반의 컴퓨터 비전 기술은 이미지 및 영상 분석 분야에서 혁신적인 발전을 이루었다[4]. 이러한 기술을 활주로 결함 검출에 적용함으로써, 활주로 이미지의 결함을 자동으로 식별하고 분류함으로써 유지보수 프로세스의 자동화 및 효율성 극대화를 실현할 수 있었다. 인공지능 기반 솔루션은 빠르고 객관적인 분석을 통해 인적 오류를 줄이고, 24시간 상시 모니터링을 가능하게 하여, 활주로 안전 관리의 패러다임을 변화시킬 잠재력을 지녔다[5]. 즉, 이러한 기술은 개발을 통해 활주로 이미지 내 결함을 자동으로 분석하도록 독려하였다.
인공지능 모델의 성능은 학습 데이터의 양과 질에 크게 의존하였다[6]. 활주로 결함 검출 모델의 정확도와 신뢰성을 높이려면 가능한 모든 결함(환경 조건, 조명 변화, 등)을 포괄하는 대규모의 고품질 학습 데이터셋이 구축되어야 했다. 특히, 군사 시설인 활주로의 특성상 데이터 수집에 엄격한 보안 제약이 따르며, 이는 실제 데이터만으로는 충분한 양의 학습 데이터를 확보하기 어렵게 만들었다. 따라서 보안 및 접근성 제약 하에서도 고품질 학습 데이터를 확보하기 위해 전략적인 접근 방식이 추가로 요구되었다. 우리는 합성 데이터를 추가로 구축하여 해당 어려움을 극복하고, 인공지능 모델 학습에 필요한 방대한 양의 데이터를 확보하였다[7].
2. 관련 연구
도로 포장 표면의 결함 탐지는 항공 운송 및 교통 안전을 확보하기 위한 필수 과제로서 꾸준히 연구되고 있다. 최근 인공지능, 특히 딥러닝 기반의 컴퓨터 비전 기술 발전은 많은 개선을 가져다줬다. 기존의 연구에서는 주로 영상 처리와 기계 학습 기반의 방법이 활용되었으나, 최근 심층 신경망(Deep Neural Networks)을 이용한 접근법이 높은 성능을 보여주고 있다.
Shi 등[8]은 도로 포장 표면 균열 탐지를 위한 CrackForest 데이터셋을 구축하여 공개했고, 다양한 알고리즘 평가를 위한 벤치마크를 제공하여 여러 연구의 기반이 되고 있다. Liu 등[9]은 심층 CNN 기반 모델인 DeepCrack을 제안하여, 포장 표면에서의 미세 균열을 높은 정확도로 탐지하였다. Fan 등[3]은 자동 균열 탐지 기술을 연구하여 활주로 유지보수 작업의 효율성 및 신뢰성을 크게 향상시킬 수 있음을 입증하였다.
한편, 엄격한 보안 규정과 제한된 접근성으로 인해, 활주로와 같은 민감한 군사 시설에서는 데이터 수집의 어려움이 크다. 이를 극복하기 위한 해결책으로 최근 합성 데이터 구축 기술이 주목받고 있다. Nikolenko[7]는 합성 데이터가 기존 데이터 수집의 한계를 효과적으로 극복할 수 있음을 논의하며, 특히 데이터가 희소하거나 수집이 어려운 환경에서 합성 데이터가 실제 데이터를 보완할 수 있음을 강조했다. 여기서 합성 데이터의 품질 평가를 위해서 SSIM (Structural Similarity Index Measure) 및 FID (Fréchet Inception Distance) 지표가 주로 사용될 수 있다[10,11].
또한, 일반적인 이미지 인식 및 객체 탐지 분야에서도 기술의 초석이 되는 연구가 활발히 이뤄져 왔다. Krizhevsky 등은 ImageNet 분류에서 성능 향상을 이루고자 심층 CNN을 이용했으며[5], 이후 해당 학습은 다양한 컴퓨터 비전 분야로 빠르게 확산되었다[4]. 특히, 객체 탐지 분야에서는 Faster R-CNN, YOLO, DETR 등 다양한 알고리즘이 제안되었으며[12,13,14], 최근 Transformer 기반의 DETR 모델은 객체 탐지의 정확성과 범용성을 크게 향상시켰다[14].
본 연구에서 소개하는 공군 활주로 크랙 데이터셋은 기존 연구들의 강점과 한계를 바탕으로 둔다. 활주로 환경에서 특히 문제가 되는 군사적 보안 제약을 고려하여, 우리는 실제 데이터와 고품질 합성 데이터를 결합한 독창적인 데이터셋을 제시한다. 이는 기존 데이터셋들이 가진 양적 제한과 데이터 편향 문제를 극복하며, 향후 활주로 결함 탐지 분야에서의 데이터 구축과 활용의 모범 사례가 될 것으로 기대된다.
3. 공군 활주로 크랙 데이터셋 개요
본 데이터셋은 “2024년 초거대 AI 확산 생태계 조성 사업”의 일환으로 한국지능정보사회진흥원(NIA)의 전담 하에 진행됐다. 이는 SGNI가 주관하고 딥노이드, 무한정보기술, GDS 컨설팅 그룹이 참여하여 약 6억 원 규모의 예산으로 2024년 7월부터 12월까지 총 6개월간 진행된 사업의 결과물이다. 이 작업의 주요 목적은 활주로 이미지 상에서 결함을 자동으로 검출할 수 있는 딥러닝 모델 학습에 필요한 방대한 양의 데이터를 제공하는 것이다.
공군 활주로 크랙 데이터셋은 총 231,347장의 활주로 이미지로 구성되어 있다. 데이터셋은 활주로 표면을 스캔하여 얻은 고해상도 영상 이미지들로 이루어져 있으며, 표준 JPG 형식과 대응되는 JSON 형식의 라벨링 데이터를 제공한다. JPG 이미지 중 결함이 포함된 이미지는 219,410장, 정상 이미지는 590장이다. 결함 유형은 우각부 균열, 균열, 줄눈재 손상, 대규모 소파 보수, 소규모 소파 보수, 스케일링 및 망상 균열, 줄눈부 스폴링, 우각부 스폴링 등으로 총 8종이다.
약 30,000장 이상의 활주로 노면 촬영 이미지와, 군이 보관 중인 자료를 활용하여 약 23만 장을 원천 데이터로 구축했다. 구체적으로, 결함 종류(type) 및 결함 정도(severity)에 따라 총 42개의 클래스로 구분되었다. 또한 군과 협의한 양질의 표본 데이터를 기반으로 합성 데이터를 구축했다. 최종적으로 실제 촬영 이미지 약 91,607장(JPG)과 그에 대응하는 라벨링 데이터(TXT) 91,607개를 포함하여, 합성 데이터를 포함한 전체 이미지를 약 20만 장으로 구성했다.
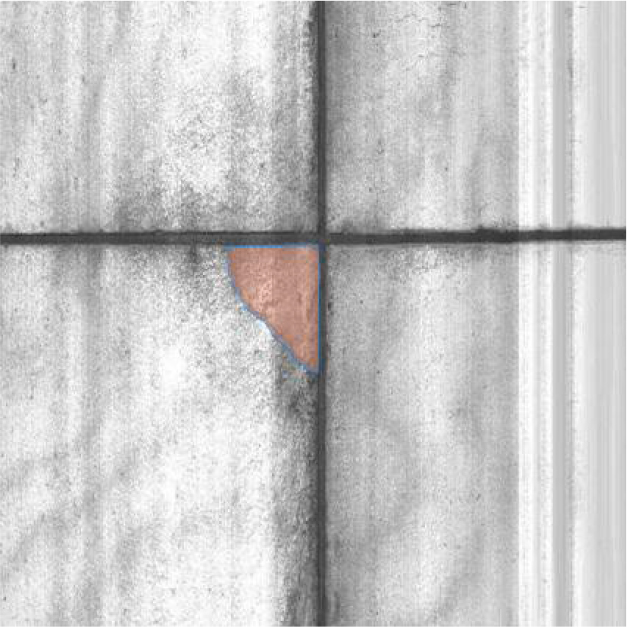
데이터셋은 활주로에서 흔히 발생하는 다양한 결함 유형을 체계적으로 포함한다. 구체적으로, 우각부 균열, 균열, 줄눈재 손상, 소규모 소파 보수, 대규모 소파 보수, 스케일링 및 망상 균열, 줄눈부 스폴링, 우각부 스폴링 등 8가지 주요 결함 유형과 함께 정상 이미지를 포함하여 총 9개의 클래스로 구성된다. 각 이미지 내의 결함 영역은 폴리곤 세그멘테이션(Segmentation)과 바운딩 박스(Bounding Box), 두 가지 방식으로 정교하게 라벨링되어 있으며, 이 라벨링 정보는 JSON 형식으로 제공한다. 이러한 다중 라벨링 방식은 객체 탐지(Object Detection)뿐만 아니라 의미론적 분할(Semantic Segmentation) 등 다양한 컴퓨터 비전 과제에 활용될 수 있어 데이터셋의 활용도를 높인다.
본 데이터셋은 활주로 내 결함 판독을 위한 인공지능 모델 개발의 핵심 기반이 되어, 활주로의 안전성 확보 및 유지보수 효율성 향상에 기여한다. 즉, 향상된 포장 평가 시스템(PMS) 제공을 위한 기초가 되어, 항공 작전의 안정성과 경제성 증대에 기여할 것으로 기대된다.
4. 데이터셋의 주요 기여 및 차별점
공군 활주로 크랙 데이터셋은 다음의 기여를 갖는다. 첫째, 군사 보안이라는 엄격한 제약과 현장 데이터 수집의 어려움에도 불구하고, 52,800장의 실제 데이터와 178,547장의 합성 데이터를 결합하여 총 231,347장의 대규모 데이터셋을 구축했다. 특히, 알파 블렌딩 데이터 합성 모델을 적용하여 실제 데이터와 유사한 고품질의 합성 데이터를 생성했다. 특히, 합성 데이터의 품질은 SSIM 지표에서 0.98163의 높은 성능과, FID 지표에서 4.2145의 낮은 오류 값을 달성했다. 이는 합성 데이터가 원천 데이터와 높은 구조적 유사성을 가지며, 통계적 특성 또한 잘 반영하고 있음을 의미한다. 합성 데이터의 높은 품질은 향후 국방, 의료, 재난 안전과 같이 실제 데이터 확보가 어렵거나 보안에 민감한 분야에서의 학습 데이터 구축의 모범 사례가 돼준다.
둘째, 활주로에서 흔히 발생하는 주요 결함을 유형별로 세분화하여 9가지 클래스로 분류한다. 특히, 각 결함에 대해 바운딩 박스와 폴리곤 세그멘테이션으로 병행 라벨링하여, 모델이 결함의 위치뿐만 아니라 형태까지 정밀하게 학습할 수 있도록 지원한다. 이는 실제 환경에서 다양한 결함 형태에 대한 강건한 모델이 개발되도록 하며, 유지보수 작업에도 필요한 정보를 정밀하게 제공할 수 있다.
셋째, 본 데이터셋은 Co-DETR 모델 학습에 활용되어 mAP50 (Mean Average Precision) 기준 0.684의 유의미한 성능을 달성하였으며, 이는 데이터셋의 학습 유용성을 간접적으로 입증한다. 특히, 원천과 합성 데이터를 모두 활용하여 학습한 모델(mAP50, 0.710)이 합성 데이터만으로 학습한 모델(mAP50, 0.674)과 성능이 0.036만 차이 난 것은 주목할 만한 점이다. 이러한 결과는 제한된 실제 데이터 환경에서 합성 데이터가 인공지능 모델의 성능을 크게 저하시키지 않음을 증명한다. 또한, 해당 방식이 데이터 부족 문제를 해결하는 하나의 열쇠임을 시사한다. 이는 데이터셋의 실용적 가치를 높이는 주요 증거이며, 향후 딥러닝 모델 구축 시 합성 데이터가 실제 데이터의 효과적인 대안 또는 보완재 역할을 수행할 수 있음을 뒷받침한다.
Ⅱ. 공군 활주로 크랙 데이터셋 상세
1. 데이터 전처리
본 논문에서 활용된 활주로 크랙 데이터는 AI 모델의 효율적이고 정확한 학습을 위해 다음과 같은 전처리 과정을 거친다. 전처리 과정은 크게 영상 수집, 전처리 보정, 영상 병합, 영상 분할, 영상 분류, 그리고 데이터 정리로, 총 6단계로 구성된다. 각 단계에 대한 상세 설명은 아래와 같다.
1) 영상 수집(Image Acquisition)
원본 표면 영상은 4 m × 10 m 크기의 이미지로 저장된 채, 외장 하드웨어에 복사하여 수집했다. 이 단계는 원천 데이터를 확보하는 초기 과정이다.
2) 전처리 보정(Preprocessing Correction)
수집된 원본 데이터 가장자리에는 검정색 선이 포함돼 있다. 이는 촬영 시 발생하는 특유의 문제로, 이를 제거하고자 영상의 좌우 100 px, 그리고 상하 200 px에 해당하는 부분을 삭제한다. 이는 데이터의 품질을 향상하고 불필요한 노이즈를 제거하여 학습 효율을 높이는 데 기여한다.
3) 영상 병합(Image Merging)
하나의 활주로에 대한 여러 4 m × 10 m 이미지를 병합하여 전체 활주로 영상을 구성한다. 이 과정에서 이미지 간의 중복을 최소화하여, 연속적이고 완전한 활주로 표면 데이터를 확보한다.
4) 영상 분할(Image Segmentation)
병합된 활주로 영상에서, 영상 분할은 공군에서 지정한 슬래브 단위 규격(7.6 m × 7.6 m, 5.75 m × 5.75 m, 4 m × 4 m)에 맞춰 수행된다. 이는 모델 학습에 용이한 크기로 데이터를 나누는 것을 의미한다.
5) 영상 분류(Image Classification)
분할된 영상들은 결함 유무에 따라 ‘결함이 없는 정상 이미지’와 ‘결함이 포함된 이미지’로 분류된다. 이는 모델 분류(Classfication) 학습 시 정답 레이블로 활용된다.
6) 데이터 정리(Data Organization)
마지막으로, 분류된 영상들은 파일 저장 구조와 일치하도록 체계적으로 정리된다. 이는 데이터의 관리 및 접근성을 용이하게 하며, 향후 모델 학습 및 평가 과정에서 데이터를 효율적으로 활용하도록 돕는다.
2. 데이터셋 개요 및 구성
공군 활주로 크랙 데이터셋은 활주로 결함 탐지 모델을 위해 구축된 대규모 이미지 데이터셋이다. 총 231,347장의 활주로 이미지로 구성되며, 모든 데이터는 활주로 표면을 스캔하여 얻은 고해상도 JPG 이미지다.
이 데이터셋은 활주로에서 발생하는 주요 결함 유형과 정상 상태를 포함하여, 총 9가지 클래스로 분류된다. 각 클래스별 이미지 수량 및 전체 데이터셋 대비 구성비는 다음과 같다.
Table 1.
Dataset Composition
Table 1에서 볼 수 있듯이, 데이터셋은 다양한 결함 유형을 고루 포함하고 있으나, 특히 ‘균열’, ‘줄눈재 손상’, ‘줄눈부 스폴링’과 같은 주요 결함 유형이 높은 비중을 차지하고 있다. 주목할 점은 ‘정상 일반 이미지’의 비율이 0.26%로 매우 낮다는 것이다. 이러한 구성은 일반적인 분류 문제와 달리, 비정상(결함) 상태의 탐지에 초점을 맞춘 불균형 데이터셋임을 나타내며, 인공지능 모델 학습 시 클래스 불균형(class imbalance)에 대한 특별한 고려(예: 가중치 부여, 소수 클래스 오버샘플링 등)가 필요함을 의미한다.
3. 메타데이터 구조 및 라벨링 형식
공군 활주로 크랙 데이터셋의 메타데이터는 데이터 활용의 편의를 위해 설계된다. 데이터 영역은 ‘영상 이미지’로, 데이터 유형은 ‘이미지’로 정의되며, 모든 원천 이미지 파일은 ‘jpg’ 형식으로 통일된다.
결함 영역에 대한 라벨링은 ‘폴리곤 세그멘테이션’과 ‘바운딩 박스’ 두 가지 유형으로 제공된다. 바운딩 박스는 결함을 직사각형 형태로 간결하게 표현하며, 폴리곤 세그멘테이션은 결함의 불규칙한 실제 형태를 픽셀 단위로 정밀하게 표현한다. 라벨링 정보는 ‘json’ 형식으로 제공되어 다양한 프레임워크 및 개발 환경에 적용되도록 돕는다.
본 데이터셋은 ‘활주로 이미지 상의 결함 판독’ 서비스 개발에 직접적으로 활용될 수 있도록 설계됐으며, 2024년에 총 231,347장의 데이터가 구축됐다.
4. 원천 데이터 및 합성 데이터 구성
공군 활주로 크랙 데이터셋은 총 231,347장의 이미지로 구성되어 있으며, 이 중 실제 활주로에서 직접 수집된 ‘일반 데이터’는 52,800장이다. 나머지 178,547장은 ‘합성 데이터’로, 인공지능 기반의 알파 블렌딩 모델을 통해 생성됐다.
합성 데이터의 압도적인 비중(전체 데이터셋의 약 77.1%)은 실제 군사 데이터 수집의 어려움을 보여준다. 군사 시설의 엄격한 보안 규정, 데이터 접근의 제한성, 그리고 특정 결함의 희소성은 실제 데이터만으로는 인공지능 모델 학습에 필요한 데이터셋 확보를 어렵게 만든다. 그렇기에 합성 데이터의 대규모 구축은 데이터셋의 확장성과 다양성을 확보하기 위한 현실적인 대안이자 필수적인 전략이었다. SSIM 및 FID와 같은 정량적 지표를 통해, 우리는 합성 데이터의 품질과 유용성을 검증했다. 이는 향후 유사한 고보안 또는 희소 분야(예: 국방, 의료, 재난 안전 등)에서의 핵심적인 데이터 구축 방법으로 채택할 수 있음을 나타낸다.
Ⅲ. 데이터셋 구축 과정
1. 데이터 구축 공정
공군 활주로 크랙 데이터셋은 체계적인 공정 과정을 거쳐 구축한다. ‘계획-수집-정제-합성-라벨링-데이터 학습-검증’의 순서로 진행하며, 각 단계별로 명확한 전략을 수립해 원활한 과업 수행을 도모했다.
여기서 ‘학습’ 및 ‘검증’ 단계는 데이터 구축 공정의 핵심이다. 이는 단순히 데이터셋을 형식적으로 정리하는 것을 넘어, 구축된 데이터셋이 실제 모델 학습에 얼마나 적합한지, 혹은 모델 성능에 ‘어떻게’ 기여를 하는지를 지속적으로 검증하는 ‘데이터 중심 인공지능 개발’ 접근 방식을 나타낸다. 이는 데이터셋의 실용적 가치와 신뢰도를 높이는 데 중요한 역할을 하며, 데이터 생성 및 정제 과정은 모델에 성능 피드백을 주어 반복적으로 개선할 수 있는 순환 구조를 장려한다.
2. 원시데이터 수집 및 확보
원시 데이터는 공군 지능정보체계관리단과 공군 제91항공공병전대 공병연구실의 협력을 통해 수집되었다. 군사 보안의 중요성을 고려하여, 보안성 검토를 완료한 이미지에 한해 주관 부대에 직접 방문하여 별도의 저장 매체에 복사하는 방식으로 데이터를 확보했다. 이러한 절차는 군사 데이터의 엄격한 보안 규정을 준수하기 위한 필수적인 과정이었다. 이때, 군과 민간 기관 간의 협의를 통해 데이터 제공 동의서를 제출하고 승인을 획득하는 과정이 선행되었다. 위 과정을 통해 총 68,351장의 실제 활주로 이미지가 확보되었다.
3. 데이터 전처리 및 정제
수집된 원시 데이터는 인공지능 학습에 적합한 형태로 변환하고자 정교한 정제 과정을 거친다. 공군 주관 부대에서 제공받은 원시 데이터는 하나의 활주로에 대해 4 × 10 m 형태의 이미지 여러 개로 구분된다. 이는 일반적인 모델 학습에 문제가 되는데, 예를 들어 객체 탐지에 사용되는 컨볼루션 신경망(CNN)은 일반적으로 균일한 크기의 입력 데이터를 선호한다. 따라서 대규모의 가변적인 이미지 크기는 학습 효율성을 저해할 수 있다.
따라서 전처리 과정을 통해 해당 이미지들을 하나의 활주로 이미지로 합친 후, 다시 슬래브 3종 규격(예: 7.6 m × 7.6 m, 5 m × 5 m)의 표준화된 크기로 분할하여 변환한다. 이러한 표준화된 단위로의 분할은 원시 데이터를 인공지능 모델이 처리하기 용이한 크기로 변환하는 주요한 엔지니어링 작업이다. 생성된 원천 데이터는 모델의 학습 효율성을 높이고, 다양한 환경에 대한 모델의 일반화 성능을 향상하는 데 기여한다. 분할 작업 이후에는 결함여부에 따라 분류하는 작업을 진행한다.
4. 합성 데이터 생성
데이터셋의 규모를 확장하고 실제 데이터 수집의 한계를 보완하기 위해, 합성 데이터 생성이 추가로 이루어진다. 군으로부터 제공받은 공군 활주로 크랙 원시 데이터를 기반으로, 결함의 종류 및 정도를 다양하게 생성할 수 있는 ‘알파 블렌딩 데이터 합성 모델’을 적용한다. 이 모델은 실제 활주로 이미지 위에 다양한 결함 패턴을 자연스럽게 합성하여, 실제와 유사한 고품질의 합성 이미지를 생성한다. 이 과정을 통해 총 178,547장의 합성 데이터가 생성됐으며, 이는 전체 데이터셋의 약 77.1%를 차지해 데이터셋의 수량 확장에 큰 기여를 했다.
5. 데이터 가공 및 라벨링
보안 규정 내에서 효율적인 작업을 수행하고자, ‘라벨미(LabelMe)’ 도구를 선정하여 활용한다. 표준 슬래브 단위로 준비된 활주로 이미지에 대해, 사전에 수립된 가공 작업 지침에 따라 바운딩 박스와 세그멘테이션 어노테이션 라벨링이 진행됐다. 해당 데이터는 인공지능 학습에 가장 간편하게 활용될 수 있는 JSON 형식으로 직렬화되어 데이터 활용성을 높인다.
Ⅳ. AI 모델링 및 성능 평가
1. AI 모델링 방법론
우리의 데이터셋의 평가를 위해, 표준 모델로 ‘Co-DETR’ 모델이 선정한다. Co-DETR은 일대다 레이블(one-to-many label) 할당 기능을 사용하여, 기존 DETR 계열보다 학습 시 높은 효율성과 성능을 지닌다. Co-DETR의 해당 능력은 단일 이미지 내에 여러 종류의 결함이 동시에 존재하거나, 동일한 결함이 여러 개 밀집하여 나타나는 활주로 환경의 특성을 고려할 때 유용하게 활용할 수 있다[15]. 즉, 모델이 복잡한 실제 시나리오에서 발생할 수 있는 밀집된 결함을 효과적으로 판단할 수 있도록 설계됨을 의미한다. 해당 모델을 통해 우리는 데이터셋이 어느 정도의 수준인지 적절히 평가할 수 있다.
모델 학습 과정은 다음과 같이 진행된다. 먼저, 전처리 과정을 거친 활주로 영상을 입력 데이터로 활용한다. 이후 적절한 로스 함수가 적용된 Co-DETR 모델을 역전파시켜 학습하며, 이미지 내 결함의 클래스와 바운딩 박스를 추출한다. 학습에 사용된 데이터는 전체 데이터셋 중 결함 이미지를 중심으로 활용하며, 학습, 검증, 평가 데이터의 비율은 각각 8:1:1로 나누어 진행한다. 모델 학습은 파이썬(Python) 환경에서 진행되었으며, 배치 사이즈(batch size)는 2, 최대 에폭(epoch)은 12의 조건으로 설정한다.
2. AI 모델 성능 평가
모델의 성능은 다양한 지표를 통해 정량적으로 평가된다. 모델의 분류 및 탐지 성능은 mAP50을 사용해 측정하는데, 이는 객체 탐지 모델의 성능을 종합적으로 평가하는 데 사용되는 핵심 지표다. 또한 합성 이미지와 원천 데이터 간의 구조적 유사성을 비교하고자 SSIM을 활용하며, FID를 계산해 실제 이미지와의 근접도를 확인한다.
: 평균
: 표준편차
: 공분산
: 안정화상수
: 실제 데이터 특징 분포의 평균·공분산
: 합성 데이터 분포의 평균·공분산
1) 분류 성능 결과
mAP50기준 목표 0.6 대비 총 7개의 결함에 대하여 0.684의 성능을 달성했다. 이는 개발된 모델이 활주로 결함을 유의미하게 탐지하고 분류할 수 있음을 입증한다. 다만, 약간의 오탐(over-detection)이 모델 학습 시 발생했는데, 원인은 지정한 슬래브 단위(7.6 × 7.6 m, 5 × 5 m) 이미지 내에 결함이 상대적으로 작게 분포하는 경우가 많아, 모델이 작은 객체에 대해 높은 리콜(recall)값을 보였기 때문이다. 이는 모델 성능 평가가 단순히 수치 달성을 넘어 실제 환경에서의 상황을 추가로 고려해야 함을 의미한다. 향후 모델 최적화 방식(예: 멀티스케일 객체 탐지 기법 적용, 고해상도 이미지 처리, 또는 작은 객체 탐지에 특화된 손실 함수 사용)을 활용하여 해당 부분을 개선해 나가는 것은 우리의 중요한 숙제가 될 것이다.
2) 합성 데이터 품질 평가
합성 데이터의 품질은 SSIM 및 FID 지표를 통해 검증한다. 원천 이미지와 합성 이미지의 유사도를 휘도, 대조, 픽셀 값의 구조적 차이를 이용하여 비교하는 SSIM 지표에서는 목표 0.9 대비 0.98163의 높은 성능을 달성했다. 이는 합성 데이터가 원천 데이터와 구조적으로 높은 유사성을 지님을 의미한다. 또한, 모델 특징의 통계적 분포를 확인하고 실제 이미지와 얼마나 가까운지를 계산하는 FID 지표에서는 목표 10 대비 4.2145의 낮은 값을 달성했다. 이는 합성 데이터가 실제 데이터의 통계적 특성을 매우 잘 반영하고 있음을 의미하며, 인공지능 학습에 필요한 다량의 데이터를 효과적으로 제공함을 입증한다.
3) 원천/합성 데이터 기반 모델 성능 비교
합성 데이터의 실질적인 학습 기여도를 평가하고자, 원천 데이터와 합성 데이터를 모두 사용하여 모델을 학습한다. 그 결과, 원천과 합성 데이터 모두 활용한 모델은 mAP50 기준 0.710을, 합성 데이터로만 학습한 모델은 mAP50 기준 0.674를 달성하여, 두 모델 간의 mAP50 차이가 0.036으로 나타났다. 이 결과는 합성 데이터가 단독으로도 실제 데이터에 준하는 학습 효과를 제공하며, 데이터 부족 문제를 효과적으로 해결할 수 있는 하나의 방식임을 입증한다. 이는 특히 실제 데이터 수집이 어렵고 비용이 많이 드는 군사 분야와 같은 보안 환경에서, 합성 데이터가 모델 개발 및 배포를 가속화하는 핵심적인 역할이 됨을 보장한다.
군사 데이터의 특성상 실제 활주로 결함 결과 이미지는 공개할 수 없으며, 본 보고서에서는 합성 샘플로 대체하여 제시한다.
Ⅴ. 실험 결과
본 연구에서는 공군 활주로 크랙 데이터에 대한 AI 학습 모델 개발 및 합성 데이터의 유효성을 검증하기 위한 다양한 실험을 수행하였다. 실험은 크게 결함 분류 성능 평가, 합성 이미지의 유사성 평가(SSIM), 시각적 튜링 테스트(VTT), 모델 성능 유사도 평가, 그리고 합성 이미지 품질 평가(FID)로 구성된다.
1. 데이터셋 구성 및 학습 환경
실험에 사용된 전체 데이터는 219,406장으로, 이 중 정상 데이터 594장을 제외한 결함 데이터가 활용되었다. Table 2에서 확인할 수 있듯이, 데이터는 학습, 검증, 평가 데이터로 다음과 같이 분할되었다.
Table 2.
Data Partitioning Status
| Data Category | Quantity | Ratio (%) | Remarks |
| Total Data | 219,406 | - | Excludes 594 normal images |
| Training Data | 175,525 | 80 | |
| Validation Data | 21,941 | 10 | |
| Test Data | 21,940 | 10 |
학습 환경은 다음과 같다.
• 개발 언어 : Python == 3.10.14
• 프레임워크 : Pytorch == 2.1.0, cudatoolkit == 11.7, mmengine == 0.10.2
• 알고리즘 : Co-DETR
• 학습 조건 : Batch size = 2, Optimizer = AdamW, Max_epoch = 12, Initial lr = 2e-4, Power = 0.9, Lr_decay = step function (milestone = 11), Weight_decay = 1e-4
2. 결함 분류 성능(mAP)
모델의 결함 분류 성능은 각 클래스별 AP (Average Precision)의 평균 값인 mAP50을 측정하여 평가한다. 이때, 목표 mAP50은 0.6 이상으로 설정한다. Table 3에 나타난 바와 같이, 총 7개의 결함 클래스에 대한 평가 결과는 다음과 같다.
Table 3.
Detection Performance Metrics by Defect Class
| Defect Class | AP |
| Crack | 0.700 |
| Corner Crack | 0.811 |
| Joint Spalling | 0.573 |
| Joint Seal Damage | 0.519 |
| Corner Spalling | 0.601 |
| Small Patching | 0.796 |
| Large Patching | 0.787 |
| mAP50 | 0.684 |
Table 3을 참조하면, 총 7개의 클래스에 대해 mAP50 = 0.684의 성능을 보였으며, 이는 목표 성능인 0.6을 달성하였다. 다만, 지정된 슬래브 단위 내 결함이 상대적으로 작게 분포하여 Recall 값이 높게 나타났다.
3. 합성 이미지 유사성(SSIM)
합성 이미지의 구조적 유사성을 평가하기 위해 SSIM (Structural Similarity Index)을 사용한다. 이때, 목표 SSIM 값은 0.9 이상으로 설정한다. 우리는 원천 배경 데이터 198장에 대해 각 이미지의 3배가 되는 594장의 합성 데이터를 준비하여 평가를 준비한다.
SSIM 계산식은 다음과 같다.
SSIM은 0과 1 사이의 값을 가지며, 1에 가까울수록 두 이미지가 유사하다고 판단한다.
실험 결과, SSIM 점수는 0.9816347로, 목표 성능인 0.9 이상을 달성했다. 이는 합성 이미지가 원천 이미지와 매우 높은 구조적 유사성을 가짐을 의미한다.
4. 시각적 튜링 테스트(VTT)
합성 이미지와 실제 이미지의 품질을 평가하기 위해 Visual Turing Test (VTT)를 수행하였다. 원천 데이터 50장과 합성 데이터 50장을 무작위로 섞은 후, 피험자가 각 이미지가 합성인지 실제 이미지인지 판단하도록 하였다. 목표 정답률은 40%에서 60% 사이로 설정되었다.
전체 정답률은 60%로, 목표 성능 범위 내에 들어왔다. 원천 데이터 정답률은 34%, 합성 데이터 정답률은 26%를 기록했다. 이는 합성 이미지가 실제 이미지와 구별하기 어려울 정도로 높은 품질을 가지고 있음을 시사한다.
5. 모델 성능 유사도
합성 데이터로 학습한 모델과 원천 데이터로 학습한 모델 간의 성능 차이를 비교하여 합성 데이터의 유용성을 검증한다. 목표는 mAP50의 5% 이내의 성능 차이다.
• 원천 데이터로 학습한 모델 결과 : mAP = 0.710
• 합성 데이터로 학습한 모델 결과 : mAP = 0.674
두 모델의 mAP50 성능 차이는 0.036으로, 이는 목표 성능인 0.05 이내를 달성했다.
6. 합성 이미지 품질 평가(FID)
합성 이미지의 품질을 평가하기 위해 FID (Frechet Inception Distance)를 사용한다. FID는 두 이미지 데이터셋의 다변량 정규분포의 거리를 계산하는 지표로, FID 값이 낮을수록 실제 이미지와 유사하다고 판단한다. 목표 FID 값은 100 이하로 설정한다.
FID 계산식은 다음과 같다.
활주로 데이터의 양이 많아, 약 1,000장씩 53세트로 나누어 FID를 계산한 후 평균값을 활용했다. 또한, 총 원천 데이터 52,206장에 대해 동일한 수의 합성 데이터를 준비했다.
실험 결과 최종 FID 평균 점수는 4.2145으로, 목표 성능인 10 이하를 달성했다. 이는 합성 이미지가 실제 이미지와 통계적으로 매우 유사함을 의미하며, 고품질의 합성 데이터가 성공적으로 생성됐음을 나타낸다.
7. 모델 시뮬레이션 결과
개발된 AI 학습 모델의 활주로 결함 검증 시뮬레이션 결과는 부록 C절에 제시되어 있다. 군 데이터의 보안상, 실제 활주로 이미지는 합성 샘플로 대체한다. 각 결함 유형에 대한 탐지 예시는 다음과 같다.
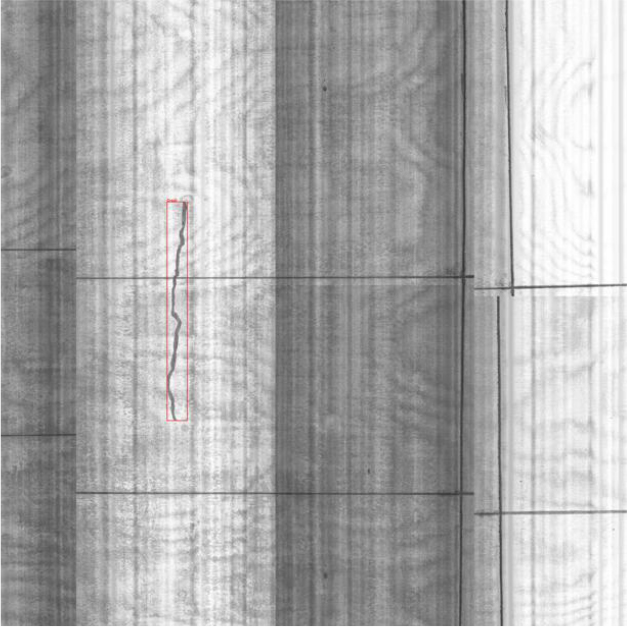
• Crack (균열) (Fig. A-16) : 활주로 표면의 균열을 정확히 탐지한다.
• Corner crack (우각부 균열) (Fig. A-18) : 활주로 모서리 부분의 균열을 탐지한다.
• Joint Spalling (줄눈부 스폴링) (Fig. A-20) : 줄눈 주변의 표면 손상을 탐지한다.
• Joint Seal damage (줄눈재 손상) (Fig. A-17) : 줄눈 재료의 손상을 탐지한다.
• Corner spalling (우각부 스폴링) (Fig. A-19) : 모서리 부분의 스폴링을 탐지한다.
• Patching (소파보수- 소규모, 대규모) (Fig. A-21) : 보수된 영역을 탐지한다.
이러한 시뮬레이션 결과는 개발된 모델이 다양한 활주로 결함을 효과적으로 식별하고 분류할 수 있음을 보여준다.
Ⅵ. 결론 및 향후 연구
1. 결론
본 논문에선 활주로 내 자동화된 결함 탐지를 위한 ‘공군 활주로 크랙 데이터셋’을 소개했다. 구체적으로, 구축 목적과 과정, 상세 정보, 이를 활용한 인공지능 모델링 및 성능 평가 결과를 세부적으로 소개했다. 군사 보안이라는 제약 속에서 총 231,347장의 대규모 이미지 데이터셋 형성의 단계적인 접근은 성공적인 데이터 구축의 밑거름이 돼줬다.
특히, 합성 데이터의 높은 구조적 및 통계적 유사성(SSIM 0.98163, FID 4.2145)은 데이터의 신뢰성을 입증한다. 또한 실제 데이터와 유사한 모델 학습 기여도(mAP50 차이 0.036)는 데이터셋의 실용적인 가치를 보여준다. 구축된 데이터셋을 기반으로 개발된 Co-DETR 모델은 mAP50 기준 0.684의 성능을 달성하여 활주로 결함 자동 검출의 가능성을 보여줬다. 우리는 해당 데이터셋이 활주로 안전 관리 및 유지보수 분야의 기술 발전에 기여할 중요한 기반 자료가 될 것으로 기대한다.
2. 향후 연구
본 연구의 성과를 바탕으로 다음과 같은 향후 연구 방향을 제안한다.
1) 모델 성능 개선
현재 모델의 오탐 원인으로 분석된 작은 결함에 대한 탐지 성능을 향상할 연구가 필요하다. 이를 위해 멀티스케일 객체 탐지 기법 적용, 고해상도 이미지 처리 기술 도입, 그리고 작은 객체에 특화된 손실 함수 및 데이터 증강 기법의 탐색을 통해 모델의 정밀도와 강건성을 더욱 향상할 수 있다.
2) 데이터셋 확장 및 다양화
현재 데이터셋은 활주로 결함 유형을 포괄하고 있으나, 향후 다양한 환경 조건(예: 강우, 설빙, 야간 등 기상 변화, 시간대별 조명 변화), 활주로 재질의 특성, 노후도에 따른 결함 양상 변화 등을 반영한 추가 데이터 수집 및 합성 연구를 통해 데이터셋의 포괄성과 현실성을 더욱 높일 필요가 있다.
3) 실시간 시스템 통합
구축된 인공지능 모델을 실제 활주로 검사 시스템에 통합하여 실시간으로 결함을 판독하고, 이를 기반으로 유지보수 우선순위 결정하거나 작업 지시를 자동화하는 시스템 개발이 필요하다. 이는 활주로 유지보수 프로세스를 효율적으로 개선할 수 있다.
4) 타 분야 적용 가능성 탐색
본 과정에서 얻은 노하우는 교량, 터널, 도로, 댐 등 다른 인프라 시설에서 인공지능 기술이 적용 가능함을 시사한다. 유사한 문제를 겪는 여러 산업 분야의 선구적인 가이드가 되어 사회 전반의 안전 및 효율성 증대에 기여가 될 것으로 기대한다.