

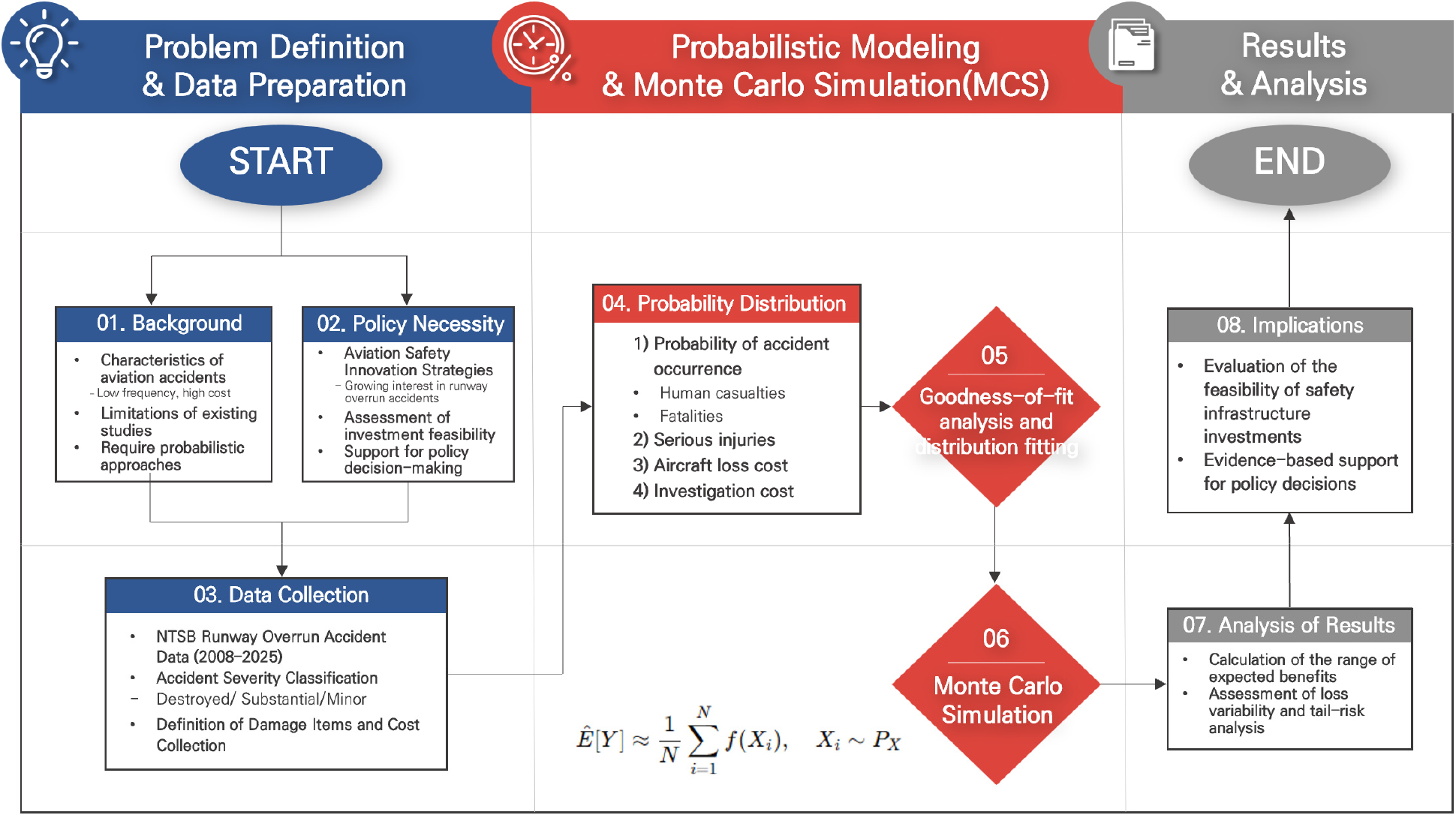
Ⅰ. 서론
1. 연구의 배경 및 목적
항공 사고 피해 방지 인프라 구축에는 설치 및 운영 비용 대비 편익을 검증하는 과정이 필수적이다. 특히 정책적 의사결정에서는 사고 발생 시 예상되는 피해 규모를 정량화하고 이를 기반으로 기대 편익을 산출하는 비용-편익 분석(B/C)이 핵심 도구로 활용된다. 이때 편익 산출의 핵심은 시설 설치로 인해 절감되는 피해 비용을 얼마나 정확하게 추정하는가에 의존하므로 항공 사고 비용 분석은 비용-편익 분석의 기초 자료 역할을 한다. 그러나 기존의 항공 사고 비용 분석은 주로 사고 건수, 평균 피해액을 기반으로 한 단순 산정 방식에 의존해 왔다. Song과 Lee [1]는 ALARP (As Low As Reasonably Practicable) 의사결정 지원을 위해 기체 손실비용, 인명손실비용, 사고조사비용 등 14개 세부 비용항목을 체계적으로 정의하고 각 항목별 산정 모형을 제시하였다. Čavka와 Čokorilo [2]는 항공기 사고의 경제적 영향을 평가하고 안전 투자에 대한 비용-편익 구조를 분석하였으며, 사고 심각도 및 탑승률에 따라 직접 비용과 간접 비용을 산출하고 기체 손상, 인명 피해, 구조·조사 비용 등 세부 항목별 비용을 산출하는 모형을 제시하였다. 이러한 접근은 항공 사고 비용을 평균 피해액 또는 고정 단가를 적용하는 단순 산정 방식으로, 사고 발생의 확률적 특성 및 사고 규모와 피해 항목 간 상관 구조를 충분히 반영하지 못한다는 한계가 있다. 특히 항공 사고는 발생 빈도는 낮지만 피해 규모가 큰 저빈도·고비용(low frequency-high consequence) 특성을 지니므로, 보다 현실적인 정량 분석을 위해서는 단순 산술이 아닌 확률분포 기반의 접근이 필요하다.
본 연구는 이러한 한계를 극복하기 위해 항공 사고를 피해 규모별로 구분하고, 각 규모에 따른 항공 사고의 발생 확률과 피해 항목을 세분화하여 확률분포 형태로 모델링하였다. 이를 기반으로 Monte Carlo 시뮬레이션을 수행하여 다양한 시나리오를 반복적으로 모의실험하고, 각 시나리오별 총 피해 비용의 분포로부터 기대 편익 분포를 제시하였다. 이러한 분석 체계는 개별 사건 사례 분석이나 단순 평균 기반의 접근법이 가지는 한계를 넘어, 다양한 시나리오에서 발생 가능한 잠재적 손실 범위를 확률적으로 산출함으로써 보다 현실성 있는 평가 근거를 제공한다. 특히 저빈도·고비용 특성을 지닌 항공 사고의 경제적 영향을 체계적으로 평가할 수 있다는 점에서, 항공 안전 인프라 투자에 대한 기대 편익 분석의 정교함과 타당성을 향상시킬 수 있다. 더 나아가, 향후 다른 유형의 저빈도·고비용 사건에도 적용 가능한 일반화된 분석 틀의 마련하는 데 기여하고자 한다.
한편, 국토교통부는 최근 항공 사고 예방과 피해 경감 달성을 목표로 제시함과 동시에 공항의 전반적인 안전성을 높이기 위한 종합 인프라 개선 계획을 수립하였다. 특히 2025년 발표된 「항공안전 혁신 방안」에서는 ‘공항 안전성 증대를 위한 인프라 개선’을 핵심 과제로 명시하며 전국 15개 공항 중 종단안전구역 권고기준에 미달하는 7개 공항에 대해 활주로 끝단에 완충 구역을 확보하거나, EMAS (Engineered Material Arresting System)와 같은 물리적 감속 장치를 설치하는 방안을 제시하였다. 이에 본 연구는 이러한 정책적 흐름과 안전성 강화 필요성을 바탕으로, 활주로 과주 사고를 대상으로 피해 확률 분포를 적용한 새로운 기대편익 산출 분석 체계를 제안한다. 이를 통해 과주 사고 피해 완화를 위한 정책·시설 투자 타당성 평가에 활용 가능한 기초 근거자료를 제공하고자 한다.
2. 접근 방법
본 연구는 활주로 과주 사고를 대상으로, 과거 사고 데이터에 기반한 사고 피해를 확률적으로 모델링한 후 Monte Carlo 시뮬레이션을 통해 안전 인프라 설치의 기대 편익을 산출하는 분석 체계를 구축하였다. 본 연구의 목적은 저빈도·고비용 특성을 가진 항공 사고의 피해 규모를 확률분포 기반으로 정량화함으로써, 극단적 사건의 잠재적 영향을 포괄적으로 반영할 수 있는 새로운 분석 방법을 제시하는 데 있다. 먼저 과거 활주로 과주 사고 사례를 수집·분석하여 기체 손상 정도를 기준으로 사고의 규모를 세 등급(상·중·하)으로 구분하였다. 이후 각 등급별 연간 사고 발생 건수를 집계하여 발생 확률을 포아송 분포로 추정함과 동시에 해당 등급에서 나타나는 피해 항목들을 확률분포로 모델링하였다. 피해 항목에는 인명 피해 가치, 기체 손실 비용, 사고 조사 비용이 포함되며 각 데이터의 특성에 따라 적합한 확률분포를 선정하였다. 이때 인명 피해 가치는 사망자 및 부상자의 수에 통계적 생명가치(value of statistical life, VSL)를 곱하여 산정하였다. 다음으로는 설정된 확률분포를 기반으로 Monte Carlo 시뮬레이션을 수행하였다. 시뮬레이션은 10,000회에 걸쳐 반복 모의를 진행하며 매 반복에서 얻어진 연간 피해비용을 통해 다양한 시나리오에서 발생 가능한 총 피해 비용의 분포를 도출하였다. 이러한 방식은 기존 분석과 달리 피해의 변동성과 꼬리 위험(tail risk)까지 고려할 수 있어 폭 넓은 피해 가능성 평가를 가능하게 한다.
Ⅱ. 본론
1. 선행연구 고찰
확률분포 모델링과 Monte Carlo 시뮬레이션은 불확실성이 큰 사업이나 프로젝트의 경제적 분석에 있어 입력 변수의 변동성과 위험 요인을 반영하기 위해 다양한 분야에서 활용되어 왔다. Lee 등[3]은 해외건설공사 비용 변동성 예측을 위해 지역별 리스크 특성을 반영하는 적정 확률분포를 선정하고 이를 기반으로 Monte Carlo 시뮬레이션을 수행하여 비용 변동 번위를 산정하였다. 또한, 기존 가정 결과와 비교함으로써 분포 선택이 분석 결과에 미치는 영향을 검토하였다. Kim 등[4]은 재생에너지 사업의 경제성 평가를 위해 제주도의 육상풍력발전 사업을 대상으로 경제적 타당성을 분석하였다. 해당 연구에서는 B/C, NPV, IRR 등 경제성 지표를 결정론적 방법과 Monte Carlo 시뮬레이션을 병행하여 산출하였으며 주요 변수의 확률분포를 설정해 10,000회 반복 시뮬레이션을 수행하였다. 이를 통해 평균값뿐 아니라 신뢰구간을 기반으로 한 경제성 평가를 제시함으로써 불확실성을 반영한 투자 판단의 중요성을 강조하였다. 이들 선행연구는 모두 불확실성을 내재한 사업의 비용·편익 분석에서 확률분포 기반 모델링과 Monte Carlo 시뮬레이션을 활용하여 단일 값이 아닌 분포와 신뢰구간 형태의 결과를 도출했다는 공통점을 지닌다. 이는 본 연구가 항공 사고 피해 비용 분석에 확률분포와 Monte Carlo 시뮬레이션을 결합하여 기대 편익을 산출하는 방법론적 근거가 된다.
희귀 사건 발생 빈도는 0 이상의 정수 값을 갖는 자료로 단위 시간·공간에서 발생 확률이 일정하다고 가정될 때 포아송 분포를 활용한 모델링이 적합하다. 포아송 분포는 평균 발생률 λ만으로 전체 확률 구조를 설명할 수 있으며, 사건이 서로 독립적으로 발생한다는 가정 하에 단위 기간 내 사건 발생 횟수를 예측하는데 널리 활용되어 왔다. Baik 등[5]은 화학물질 비축 신뢰성 프로그램에서 결함 발생 횟수를 포아송 확률변수로 모델링하여 Monte Carlo 시뮬레이션을 수행하였다. 특히 결함 비율 추정 시 표본 오차와 불확실성을 반영하기 위해 포아송 분포를 기반으로 난수를 생성하고 이를 통해 기댓값과 신뢰구간을 산출하였다. 이러한 접근은 희귀 사건의 발생 확률 추정에 있어 포아송 분포 기반 시뮬레이션의 유용성을 입증하였다. Kim 등[6]은 대설 재난 발생확률을 정량화하고, GIS를 이용해 지역별 확률 지도를 작성하여 정책 활용 근거를 마련하는 과정에서 대설 재난의 저빈도·고피해 특성을 고려해 포아송 분포를 활용하였다. 이를 통해 단계별 평균 발생빈도를 기반으로 연간 발생확률을 산정하였으며, 그 결과 포아송 모형이 대설재난과 같이 발생 간격이 불규칙하고 피해 편차가 큰 재난 유형의 확률 추정에 유효함을 확인하였다. Wali 등[7]은 미국 테네시주 도로를 대상으로 안전성능함수(Safety Performance Function, SPF)를 개발하면서. 교통사고 발생 건수는 일정 시간·공간 단위에서 발생하는 0 이상의 이산형 가산자료라는 점에서 평균 발생률을 매개 변수로 하는 포아송 분포를 기본 가정으로 삼았다. Lim [8]은 대전광역시 79개 행정동을 대상으로 2015–2020년 교통사고 발생 건수를 분석하면서 포아송 분포를 기반으로 시공간 베이지안 모형을 적용하였다. 이처럼 사고 발생과 같이 낮은 빈도이면서 확률적 특성을 가지는 사건을 분석할 때, 포아송 분포를 기본 모형으로 설정하는 방법은 타당성을 지니며 따라서 본 연구에서도 사고 발생 확률을 확률분포로 나타내기 위해 포아송 분포를 채택하였다.
영-과잉(zero-inflation) 데이터에 대해서는 이러한 특성을 고려한 확률 분포를 적용하는 연구들이 활발히 진행되어 왔다. Choi 등[9]은 보험 데이터 분석에 특화된 계수 데이터 모형화 연구를 진행하며 특히 보험 처리 건수처럼 ‘0’이 많고 분산이 평균보다 큰 과대산포 및 영-과잉 현상이 나타나는 데이터에 최적화된 분석 방법을 제시하였다. 포아송, 음이항 회귀모형과 함께 제로팽창 모형들을 비교 분석하여, 실제 보험 데이터에서 제로팽창 음이항 분포(Zero-inflated Negative Binomial, ZINB)가 가장 효율적임을 실증적으로 보여주었다. 따라서 본 연구에서는 영-과잉 특성을 띄는 과주 사고 사상자 수에 대해 포아송 분포, 음이항 분포 2형(negative binomial type 2, NB2)과 제로팽창 음이항 분포(ZINB)를 비교 검증하고, 가장 적합한 분포를 적용하였다.
삼각분포는 최소값(min), 최빈값(mode), 최대값(max)의 세 매개변수만으로 정의 가능하다는 면에서 자료가 제한적인 상황에서도 쉽게 적용할 수 있는 확률분포로 평가된다. Geberemariam [10]은 사회기반시설 프로젝트의 재무적 불확실성과 확률적 위험을 반영하기 위해 다양한 확률분포 사용을 권장하였으며, 이를 통해 Monte Carlo 기반 분석모델을 제안하였다. 특히 데이터가 부족한 상황에 삼각분포의 활용이 적합성을 강조함과 동시에 제약이 있는 프로젝트 환경에서의 적용 가능성을 구체적으로 제시하였다. Bidhandi 등[11]은 프리패브 건설의 JIT 전략 평가를 위해 Monte Carlo 시뮬레이션을 수행하면서 활동 시간의 불확실성을 반영하기 위해 삼각분포를 활용하였다. 건설 현장의 활동 기간은 날씨, 자원 가용성, 현장 제약 등 외부 변수에 민감하게 반응하며, 이에 따라 활동별 소요 시간은 고정된 분포보다는 가장 가능성 있는 시나리오에 변동 폭을 적용하여 낙관적·비관적 시나리오를 설정해 삼각분포의 세 매개변수를 구성하였다. 이와 같이, 삼각분포는 최소한의 정보만으로도 불확실성을 반영할 수 있어, 통계적 자료가 제한적인 항공사고 피해 비용 분석에서 기체 손실 비용과 사고 조사 비용의 확률모델로 적용하기에 적합하다. 추가로, 본 연구에서는 사업의 타당성 검토에 있어 비용 추정의 정확도는 ±30% 수준이 유용하다는 전문가들의 의견에 따라 삼각분포의 최소값과 최대값은 최빈값을 기준으로 ±30% 범위로 설정하였다[10].
2. 자료의 수집 및 분석
본 연구에서는 미국 국가교통안전위원회(National Transportation Safety Board, NTSB)가 제공하는 항공사고 데이터 베이스를 활용하였다. 분석 대상 기간은 2008년부터 2025년으로, 해당 기간 동안 발생한 활주로 이탈 사고 중 과주(overrun)로 분류되는 사고 사례만을 선별하였다. 사고 선별은 국가교통안전위원회(NTSB)에서 공개하는 사고조사 보고서의 서술 내용을 검토하여 사고 유형을 식별하는 방식으로 이루어졌다. 사고 심각도는 기체 손상 정도를 기준으로 상(Destroyed), 중(Substantial), 하(Minor) 세 등급으로 구분하였다. 이후 각 등급별로 연도별 과주 사고 발생 건수를 집계하였으며, 해당 사고에 발생한 총 사망자 수와 부상자 수를 산출하였다.
사망자에 대한 통계적 생명가치(VSL)은 OECD의 「Mortality Risk Valuation in Environment, Health and Transport Policies」 보고서에 제시된 값을 활용하였다[12]. 사망자 피해 가치는 OECD 국가 기준 VSL을 기반으로, 1인당 GDP 비율과 소득탄력성 계수를 적용한 환산식에 따라 한국 기준 VSL로 변환하였다. 부상자 피해 가치는 유럽교통장관회의(ECMT) 기준을 적용하여 사망자 VSL의 13%로 산정하였다[13]. 이 값들은 각 사고 등급별 사망 및 부상자 수와 곱하여 인명 피해 비용을 산출하는데 활용하였다.
항공기 기체 손실 비용 산정은 미국 연방항공청(Federal Aviation Administration, FAA)의 「Unit Replacement and Restoration Costs of Damaged Aircraft」 (2018) 보고서를 참조하였다[14]. 본 연구에서는 특히 ‘Table 5-2: 2018 Passenger Air Carrier Fleet Sizes and Values’에 제시된 항공기 분류별 보유 대수와 평균 시장 가치를 활용하였다. 해당 자료를 기반으로, 각 항공기 분류별 시장 가치를 확인한 후 여객 항공사의 보유 항공기 수를 가중치로 부여하여 전체 여객 항공기의 평균 시장 가치를 산출하였다. 해당 가중평균값은 사고 발생 시 기체 손실 비용을 산정하기 위한 기준값으로 활용되었다.
항공 사고 조사 비용 산정은 미국 연방항공청(FAA)의 「Aviation Accident Investigation Costs」 (2018)를 활용하였다[15]. 본 연구에서는 특히 ‘Table 8-3: Total FAA Investigation Costs for Accidents and Incidents by Highest Injury and Damage Categories’을 참고하였다. 해당 자료는 사고 유형 및 손상 정도에 따라 구분된 사고 건수, 평균 투입 조사관 시간, 및 사건당 평균 조사 비용을 제공하고 있으며, 이를 통해 사고 심각도별로 차등화된 조사 비용을 추정할 수 있었다. 본 연구에서는 이 데이터를 기반으로 사고 규모 수준에 따른 평균 조사 비용을 산정하였다.
비용 산정 과정에서 소비자물가지수는 세계은행(World Bank)의 「Consumer price index (2010 = 100) - United States」[16]를, 환율은 한국은행 ECOS의 「원화의 대미달러, 원화의 대위안 환율」[17]을 활용하여 2024년 1월을 기준으로 변환하였다.
3. 연구방법론
1) 포아송 분포
포아송 분포(Poisson distribution)는 단위 시간 또는 단위 공간 내에서 특정 사건이 발생하는 횟수를 설명하기 위해 사용되는 이산형 확률모형이다. 이 분포는 다음과 같은 두 가지 기본 가정을 전제로 한다. 첫째, 사건은 서로 독립적으로 발생한다. 둘째, 단위 구간에서 사건이 발생하는 평균 빈도(발생률, 𝜆)가 일정하다. 이러한 특성은 항공사고와 같이 발생 빈도가 낮고, 특정 기간 동안 평균 발생률이 크게 변동하지 않는 사건을 모형화하는 데 적합하다[18].
포아송 분포의 확률질량함수(probability mass function, PMF)는 식 (1)과 같이 정의된다.
여기서, : 단위 시간(또는 공간) 내 사건 발생 횟수
: 실제 관측된 사건 발생 건수
𝜆 : 단위 시간(또는 공간) 내 평균 사건 발생 건수
포아송 분포의 평균과 분산은 모두 λ로 동일하다. 이는 사건 발생의 변동성이 평균과 동일한 수준에서 나타난다는 의미이며, 이를 등분산성(equidispersion)이라 한다. 이러한 특성은 항공사고와 같이 저빈도 사건을 모델링할 때 유용하며, 특히 연간 사고 발생 건수가 비교적 작고 관측 기간 동안 평균 발생률이 안정적일 때 적합하다.
본 연구에서는 연도별 항공사고 발생 건수 데이터를 활용하여 최대우도추정법(Maximum Likelihood Estimation, MLE)을 적용하여 포아송 분포의 λ를 추정하고, 모델 적합도는 아카이케 정보 기준(Akaike Information Criterion, AIC)을 통해 평가하였다. 이를 바탕으로 향후 1년 동안 발생할 수 있는 사고 건수의 확률분포를 도출하였다.
2) 음이항 분포
음이항 분포(negative binomial distribution, NB)는 사건 발생 횟수 데이터에서 평균보다 분산이 큰 과산포(overdispersion) 현상을 설명하는 데 적합한 이산 확률분포이다. 모형화 방식에 따라 NB1, NB2로 구분되며, NB1 모형은 분산이 평균에 비례하는 구조를 가지는 반면, NB2는 분산이 평균의 제곱에 비례하는 형태를 보인다.
한편, 실제 데이터에서 ‘0’이 과도하게 나타나는 경우에는 이를 보완하기 위해 제로팽창 음이항 분포(ZINB)를 활용한다. ZINB는 과산포 뿐 아니라 영 과잉(zero-inflated) 현상까지 동시에 처리할 수 있다는 장점이 있다. 따라서 사고 데이터와 같이 대부분의 경우 피해가 없으나 일부 경우에 큰 피해가 발생하는 상황에서는 단순 NB 모형보다 ZINB 모형이 실제 분포를 더 잘 설명할 수 있다.
3) 사망자 및 부상자 수 확률 분포 적합도 검정
본 연구에서는 사고 데이터가 과산포와 영 과잉 특성을 지니는 경우가 많다는 점을 고려하여, 사망자 및 부상자 수에 대한 확률 분포를 모형화하는 과정에서 포아송, NB2, ZINB 모형을 비교·검토하고, 그 중 적합한 분포를 찾고자 하였다. 이를 위해 상·중·하 등급별 피해 항목 중 사망자와 부상자 수의 확률 분포에 대하여 후보 분포군(Poisson, NB2, ZINB)의 적합성을 비교 및 평가하였다. 이를 위해 각 항목별 데이터를 대상으로 로그우도(log-likelihood), 아카이케 정보 기준(AIC), 베이즈 정보 기준(Bayesian Information Criterion, BIC)과 같은 정보 기준을 산출하고, 과산포(overdispersion) 지수 및 0 발생 비율(zero rate)을 함께 분석하였다. 이러한 복합적인 판단 지표를 활용함으로써 각 분포가 데이터의 특성을 얼마나 적절히 반영하는지 확인하였다.
모형 비교에 널리 사용되는 아카이케 정보 기준(AIC)과 베이즈 정보 기준(BIC)은 다음과 같이 정의된다.
AIC는 모형의 복잡성과 적합도를 동시에 고려하는 지표로, 해당 식에서 는 모형의 자유모수(parameter) 계수, 는 최대우도(maximum likelihood) 값을 의미한다. AIC 값이 작을수록 데이터 적합도가 높으면서 과적합 위험은 상대적으로 낮다.
반면, BIC는 AIC와 유사하지만 표본 크기 n에 따라 모수 개수에 대한 패널티를 강화한 형태이다. 따라서 BIC 값이 작을수록 모형의 설명력이 높고 단순성이 유지된다고 본다.
Table 1의 사망자와 부상자 수의 확률 분포 적합도 검정 결과, 상-사망, 상-부상, 중-부상, 하-부상 항목에서는 NB2 분포가 다른 후보 분포보다 우수한 적합도를 보였다. NB2 분포는 포아송 분포에 비해 평균과 분산이 크게 다른 과산포 데이터를 효과적으로 설명할 수 있으며, 특히 사고 건수 데이터와 같이 분산이 평균을 크게 초과하는 경우에 적합하다. 상-사망 항목에 대한 NB2 모형 적합 결과, 평균은 3.866, 분산은 552.58로 산출되었으며 이에 따른 과산포 지수(Overdispersion Index, ODI)는 142.93으로 확인되었다. 상-부상 항목의 경우에도 평균은 0.165, 분산은 0.524, 과산포 지수(ODI)는 3.17을 보여 NB2가 적절한 것으로 판단되었다. 중-부상 및 하-부상 항목 또한 과산포 지수(ODI)가 각각 1.92와 4.26으로 나타나 NB2 모형이 가장 적합한 것으로 확인되었다.
Table 1.
Goodness-of-Fit Analysis Results for the Distribution of Fatalities and Injuries by Damage Severity Level
반면, 중-사망 항목의 경우 전체 데이터의 88.99%의 값이 0으로 나타나 일반적인 음이항(NB2) 분포로 설명하기 어려운 특성을 보였다. 이에 따라 0 값이 과도하게 많은 데이터를 모형화할 수 있는 ZINB 분포를 적용하였다. 모수 추정 결과, α = 0.4676, π = 0.79899로 산출되었으며 이는 사망 사고가 매우 드물게 발생하는 동시에 다수의 구간에서 사망자가 전혀 발생하지 않는 특성을 적절히 나타낸다. 하-사망 항목의 경우에는 평균과 분산이 동일(λ = 0.01449)하고 과산포 지수가 정확히 1.0으로 나타나 포아송 분포가 적합하였다. 이는 발생 확률이 희박한 희귀 사건인 하등급 사망 사고에 대한 전형적인 통계적 특성을 잘 반영한다.
분포 적합도 분석 결과, 사고 등급 및 피해 유형에 따라 통계적 분포 특성이 상이함이 확인되었다. 특히, 사망 사고의 경우 사고 등급이 낮을수록 발생 빈도가 급격히 감소하였으며, 중·하등급 사망 사고는 ‘희귀 사건’ 특성을 보이며 0 발생 비율이 매우 높았다. 부상 사고의 경우 피해 규모는 작지만 여전히 과산포가 존재하여 단순 포아송 모형보다 NB2 모형이 적합하였다. 따라서 Monte Carlo 시뮬레이션을 통한 기대비용 산정 과정에서는 각 항목별로 최적 분포를 그대로 반영하여 입력 분포를 설정하였다. 이는 분포 적합도가 낮은 모형을 사용할 경우, 희귀 사건이나 과산포 현상을 제대로 반영하지 못해 피해비용 추정값의 편향이 발생할 수 있다는 점에서 의미를 가진다.
4) 삼각 분포
삼각 분포(triangular distribution)는 최소값 , 최빈값 , 최대값 의 세 가지 매개변수만으로 정의되는 연속 확률분포로, 데이터가 충분하지 않은 상황에서도 간단하게 추정치를 반영할 수 있다는 장점이 있다. 특히 자료가 제한적일 때 전문가의 판단이나 기존 사례를 활용하여 합리적인 추정 범위를 설정할 수 있어 불확실성을 반영한 비용 분석에 활용된다.
삼각 분포의 확률밀도함수는 다음과 같이 정의된다[19].
본 연구에서는 관련 데이터가 충분히 축적되지 않은 기체 손실 비용과 사고 조사 비용에 대해 최빈값을 기준으로 최소값과 최대값을 각각 ±30% 범위에서 설정하여 삼각분포를 적용하였다.
5) Monte Carlo 시뮬레이션
Monte Carlo 시뮬레이션은 확률적 불확실성이 존재하는 복잡한 시스템을 분석하기 위해 난수 생성과 반복 계산을 이용하는 수치 해석 기법이다[20]. 해당 기법은 확률분포를 따르는 입력변수를 다수 생성하고, 각 표본에 대해 모형을 반복 실행하여 결과 값의 확률분포를 근사적으로 추정하는 데 사용된다. 수행 절차는 다음과 같다. 우선, 분석 대상 변수의 특성에 따라 다양한 형태의 확률 분포를 정의한다. 다음 단계에서는 정의된 분포로부터 난수를 생성하며, 역변환법(Inverse Transform Sampling)과 난수 변환 기법을 활용하여 해당 분포를 따르는 표본을 얻는다. 이후, 생성된 표본을 분석 모형에 대입하여 결과를 계산하고, 이러한 계산을 충분히 큰 횟수 만큼 반복하여 결과 값의 확률분포를 추정한다. 반복 횟수 이 증가할수록 추정 결과의 표준오차는 비율로 감소하여, 보다 정밀한 근사치를 얻을 수 있다.
Monte Carlo 시뮬레이션은 입력변수의 불확실성이 복잡하게 상호작용하는 경우나, 해석적 해법이 존재하지 않는 문제에 효과적으로 적용 가능하다. 본 연구에서는 총 10,000회 반복 시행을 통해 개별 피해 항목의 불확실성을 반영한 종합적 피해 비용 평가를 가능하도록 하였다. 이때 사고 1건당 피해 비용은 다음과 같이 정의하였다.
여기서, : 사고 의 피해 비용
, : 사고 에서 발생한 사망자, 부상자 수
, : 사망자, 부상자 1인당 VSL (통계적 생명가치)
, : 사고 에서 발생한 기체 손실 비용, 사고 조사 비용
4. 연구결과
1) 피해 비용
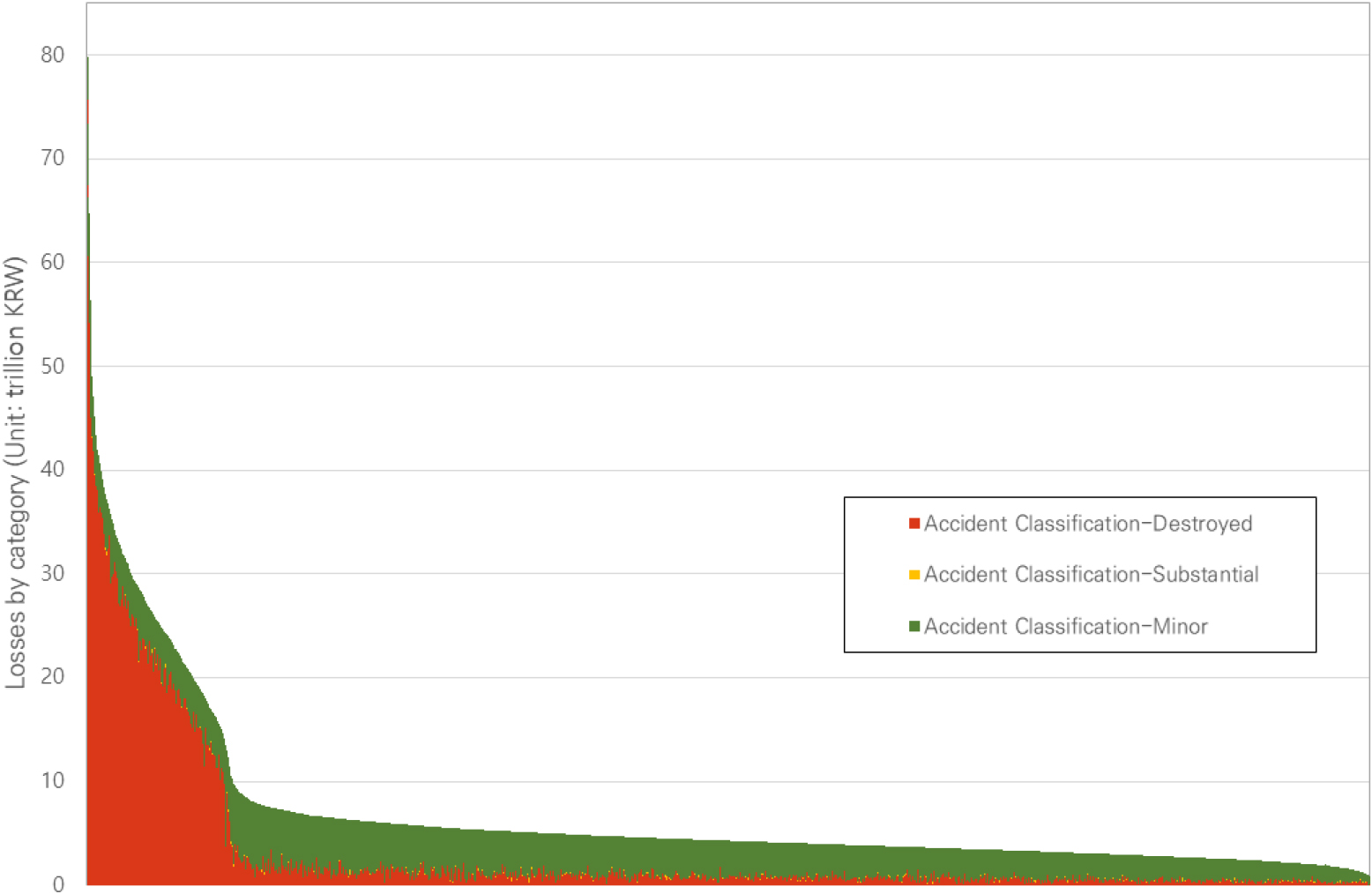
본 연구에서는 Monte Carlo 시뮬레이션을 10,000회 반복 수행하여 각 시행에서 사고 등급별(상·중·하) 피해액을 산정한 후, 이를 합산하여 총 피해액을 산출하였다. Table 2의 피해 비용 주요 통계 지표 분석 결과, 총 피해액의 평균은 6조 7,400억 원, 표준편차는 8조 400억 원으로 산출되었으며 중앙값은 4조 2,700억 원으로 평균보다 낮았다. 이는 일부 시행에서 발생한 대규모 피해가 평균을 증가시킨 결과로, 기존 사고 통계에서 사망자 수가 0명 또는 다수로 나타나는 극단적 분포 특성과 일치한다. 실제로 본 연구의 확률분포 추정에서도 일부 회차에서 다수 사망 시나리오가 발생하여 피해액이 크게 산출되었다.
피해 비용의 주요 통계 결과, 최소값은 4,300억 원, 제1사분위(Q1, 하위 25%)는 3조 2,000억 원, 제3사분위(Q3, 상위 25%)는 5조 8,100억 원으로 나타났다. 특히 Q3와 평균의 차이는 상대적으로 작으나, 최대값은 79조 8,300억 원으로 평균의 약 11.8배에 달하여 상위 구간에서 피해액 변동 폭이 매우 크다는 점을 확인할 수 있었다.
Table 2.
Key Statistical Indicators of Damage Costs

Monte Carlo 시뮬레이션 1회당 총 피해액의 히스토그램인 Fig. 2에서, 피해액 분포는 좌측에 주 모드(main mode)가 형성되고, 우측으로 꼬리가 길게 이어지는 양의 비대칭 형태를 보였다. 평균 이하 구간에 데이터가 집중되는 경향을 보였으며 10조 원 이하 구간에서 빈도가 급격히 감소한 뒤, 10조–30조 원 구간에서 낮은 빈도로 유지되다 30조 원을 초과하는 구간에서는 일부 값이 집중되는 양상이 확인되었다.
특히, 99% VaR은 약 40.32조 원으로 산출되어 분포의 극단 구간을 반영하였다. 이는 평균이나 분산과 같은 일반적 통계지표로는 설명하기 어려운 tail risk, 즉 분포의 꼬리 부분에서 발생하는 극단적 손실 위험을 나타낸다. 따라서 피해액 분포가 정상적인 범위를 넘어서는 대규모 손실의 특성을 포함하고 있음을 확인하였다. 이러한 상위 꼬리 구간은 상위 등급 대규모 피해와 중·하위 등급 피해가 동시에 발생한 시나리오에서 형성된 것으로 보인다.
2) 등급별 피해액 기여도 분석
Monte Carlo 시뮬레이션 피해액 산출 결과를 등급별(상·중·하)로 구분하여 피해액 기여도와 통계 지표를 분석하였다. Fig. 3에서는 각 시뮬레이션에서 등급별 피해액이 차지하는 비율이 잘 드러나 있다. 전체 피해액 합계 대비 각 등급별 기여율은 상 등급이 65.76%, 하 등급이 33.81%, 중 등급이 0.42%로 나타났다. 이는 상 등급 피해가 전체 피해액의 절반 이상을 차지하며, 단일 고액 피해 사건이 전체 손실 규모에 미치는 영향이 절대적으로 크다는 점을 확인할 수 있다. 하 등급 피해는 상대적으로 피해 규모가 작지만, 빈발하는 특성으로 인해 전체 피해액의 약 3분의 1을 차지하는 수준의 기여도를 보였다. 반면, 중 등급 피해는 전체 피해액 중 1% 미만의 비중을 차지하며, 총 피해액에 대한 직접적 기여가 제한적인 것으로 분석되었다.
평균 피해액을 비교하면, 상 등급은 4조 4,313억 원으로 하 등급(2조 2,786억 원)의 약 1.94배, 중 등급(286억 원)의 약 15.5배 수준이었다. 표준편차를 살펴보면, 상 등급은 7조 9,660억 원으로 평균의 약 1.8배에 해당하며, 이는 하 등급(1조 778억 원, 평균 대비 약 0.47배)에 비해 변동성이 훨씬 크다는 것을 의미한다. 중 등급의 표준편차는 498억 원으로 평균의 약 1.74배였으나 절대 규모가 작아 전체 변동성 기여도는 미미했다.
최소 피해액과 최대 피해액의 차이를 보면, 상 등급은 최소 약 1.39억 원에서 최대 약 75조 7,428억 원까지 변동하며 극단값의 폭이 매우 컸다. 이는 하 등급의 최대값(약 9조 6,002억 원)의 약 7.9배, 중 등급의 최대값(약 5,809억 원)의 약 130배에 해당한다. 하 등급은 최소 약 6억 원 수준에서 시작해 최대 9조 원대까지 분포하였으며, 변동 폭은 크지만 상 등급에 비해서는 제한적이었다. 중 등급은 최소값과 최대값 모두 상대적으로 작아 피해액 규모에서의 영향력이 제한되었다.
분위수 분석 결과, 상 등급 피해액은 Q3 (상위 25%) 기준으로 약 5조 6천억 원을 넘어섰으며, 이는 하 등급 Q3 (약 3조 7천억 원)의 1.5배 수준이었다. 중 등급은 Q3 값이 약 500억 원 수준으로 다른 등급과 비교할 때 현저히 낮았다. 또한, 95% 분위 이상의 상위 꼬리 구간에서는 상 등급 피해가 평균 대비 1.7배, 99% 분위에서는 약 2.4배에 달해 극단값 구간에서 상 등급 피해의 영향력이 두드러졌다.
이러한 결과는 상 등급 피해가 발생 빈도는 낮지만, 한 번 발생 시 단일 사건이 전체 피해액 분포의 우측 꼬리를 크게 끌어올린다는 점을 보여준다. 반면 하 등급은 빈발하지만 사건당 피해액이 비교적 작아 평균 수준의 피해액 형성에 기여하는 경향이 강했다. 중 등급은 빈도와 피해 규모 모두 제한적이어서 전체 재정 부담에 미치는 영향이 미미했다. 따라서 피해액 분포의 특성을 해석할 때는 평균값만을 제시하기보다, 등급별 기여율과 변동성, 그리고 분위수 기반 극단값 분석을 함께 고려하는 것이 분포의 비대칭성과 재정적 위험의 특성을 이해하는 데 필수적임이 확인되었다.
Ⅲ. 결론
본 연구는 과거 활주로 사고 데이터를 기반으로 피해 규모를 등급별로 구분하고 각 피해 항목에 적합한 확률분포를 결정한 뒤, Monte Carlo 시뮬레이션을 수행하여 각 등급별 연간 피해비용의 분포 특성 및 기여도를 정량적으로 규명하였다. 항목별 최적 분포의 경우 데이터 특성에 따라 서로 다른 통계적 분포가 적합한 것으로 나타났으며, 이는 사고 피해 데이터를 단일 분포로 단순화하는 접근의 한계를 보여주며 항목별 최적 분포를 고려해야 함을 보인다.
피해 분포의 통계적 특성을 살펴본 결과, 본 연구에서 산출된 피해액 분포는 좌측에 주 모드를 두고 우측 꼬리가 길게 늘어진 양의 비대칭 형태를 나타냈다. 특히, 극히 낮은 확률로 발생하는 사건이 전체 피해액에서 차지하는 비중이 매우 큰 꼬리 위험(tail risk)의 존재가 확인되었다. 이러한 꼬리 위험 특성은 저빈도 사건의 영향이 과소 평가되는 것을 방지하기 위해 평균·분산 중심의 지표 체계 외에 중앙값, 분위값, Value-at-Risk (VaR)와 같은 극단값 기반 지표를 병행할 필요성을 뒷받침한다. 이를 통해 극단값의 영향력을 완화하고 정책적 판단의 왜곡을 줄일 수 있다.
등급별 피해액 기여도 분석 결과, 전체 피해액의 약 65.8%가 상 등급 사고에서 발생하여 단일 대형 사건이 전체 손실 규모를 좌우하는 경향이 확인되었다. 하 등급은 사건당 피해 규모는 작지만 빈발 특성으로 인해 약 33.8%를 차지하며 평균 수준의 피해액 형성에 크게 기여하는 반면, 중 등급은 발생 빈도와 피해 규모가 제한적으로 전체 피해액 기여율이 1% 미만에 그쳤다.
본 연구는 항공사고의 피해 규모를 확률분포 기반으로 분석하여, 평균값에 의존한 기존 방식의 한계를 넘은 기대비용 평가 체계를 제시하였다. 제안된 기대비용 기반 접근법은 EMAS와 같은 피해 완화 시설의 효과 분석에도 활용될 수 있으며, 단순 설치비 대비 절감액 산정이 아닌 확률적 기대편익을 고려한 보다 현실적인 정책 및 투자 평가를 가능하게 한다. 특히, 효과 분석에 있어 사고 발생 확률과 피해 감소 효과를 결합한 기대 피해액 산정이라는 점에서 더욱 의의가 있다.
다만, 본 연구는 전체 항공사고 데이터를 기반으로 수행되었기 때문에 개별 공항의 특성이나 기상·운영 환경, 항공기 운항 패턴 등 세부 변수를 충분히 반영하지 못했다는 한계가 있다. 따라서 향후 연구에서는 공항별 세부 자료를 확보하고 기상 변화, 활주로 조건, 항공기 기종 등을 결합한 정밀 분석을 수행할 필요가 있다. 또한 본 연구에서 제안한 분석 프레임은 항공 분야에 국한되지 않고 철도·도로·해운·산업재해 등 다양한 재난 및 사고 분야에도 확장 적용이 가능하다는 점에서 활용 가능성이 크다.
본 연구는 저빈도·고비용(low frequency-high consequence) 특성을 지닌 항공 사고의 피해 규모 불균형성과 꼬리 위험(tail risk)을 정량적으로 규명하고, 평균값 중심의 평가에서 벗어나 상위 분위값, VaR, 그리고 기대비용 기반 접근을 통합하였다. 이를 통해 향후 보다 효율적인 위험관리 전략 수립에 기여할 수 있을 것으로 기대된다.
